OpenRouter Fusion: cuándo un panel de modelos supera a uno solo
Reconócelo, que esto lo hacemos todos. Tienes una pregunta gorda, de esas donde equivocarte cuesta caro, y
empieza el ritual.
“A ver qué dice Claude.”
“A ver qué dice GPT.”
“A ver qué dice Gemini, que a veces sorprende.”
Y el remate: “a ver cuál se ha inventado menos cosas, que hoy tengo el día tonto”.
Pues bien, OpenRouter ha cogido ese ritual artesanal de copiar y pegar el mismo prompt en tres pestañas y lo ha
empaquetado en una sola llamada de API. Se llama Fusion y lo presentaron el 12 de junio de 2026
(OpenRouter).
Lo interesante no es el titular de marketing. Lo interesante es el cambio de mentalidad que hay debajo. Vamos a
verlo con calma.
En este post vas a encontrar:
- Qué es Fusion y por qué no es “un modelo nuevo” sino una capa de orquestación
- Cómo funciona el pipeline por dentro: panel, juez y sintetizador
- Las dos formas de llamarlo desde la API, con código real
- Qué dicen los benchmarks de DRACO y dónde está la trampa metodológica
- Cuándo merece la pena montar este comité y cuándo es tirar el dinero
¿Qué es OpenRouter Fusion y por qué no es “otro modelo”? ¶
Fusion es una capa de orquestación que manda tu prompt a varios modelos en paralelo, hace que un modelo juez
compare las respuestas y luego genera una única respuesta final apoyada en ese análisis. No es un modelo
entrenado desde cero. Es un flujo de trabajo convertido en primitiva de API
(OpenRouter).
Esa es la frase que tienes que retener. Porque el error de lectura más común con Fusion es pensar que OpenRouter
ha entrenado un nuevo cerebro que aplasta a Opus y a GPT. No. Lo que ha hecho es coger varios cerebros que ya
existen y ponerlos a deliberar.
Si vienes de leer nuestra comparativa de los mejores modelos de IA para código en
2026, ya sabes que en este oficio nadie gana en
todo. Opus razona mejor, GPT ejecuta sesiones largas, Gemini te salva con el contexto enorme. Fusion parte justo
de esa idea: si ningún modelo gana siempre, ¿por qué obligarte a elegir uno?
🔑 Fusion no responde a la pregunta “¿qué modelo uso?”. Responde a una pregunta distinta: “¿y si no tengo que
elegir?”.
La clave técnica, y esto sí importa para developers, es que todo el pipeline se ejecuta en el servidor de
OpenRouter. Tú haces una sola llamada y por debajo se disparan varias. Para tu código es casi idéntico a
invocar un modelo normal.
Cómo funciona Fusion por dentro ¶
El recorrido de una petición Fusion tiene cinco pasos bien definidos según la documentación oficial
(OpenRouter):
- Mandas la petición con
model: "openrouter/fusion". El router resuelve el alias a un modelo real y le
engancha la herramientaopenrouter:fusion. - Tu modelo lee el prompt y decide si la tarea merece deliberación. Si la merece, invoca la herramienta.
- El panel (un conjunto de modelos) responde a tu prompt en paralelo, cada uno con búsqueda web y lectura de
páginas activadas. - El juez recibe todas las respuestas del panel y las compara. Ojo: las compara, no las fusiona. Devuelve un
análisis estructurado en JSON. - Tu modelo recibe ese análisis y escribe la respuesta final.
Fíjate en el paso 4, que es donde está la chicha. El juez no hace una media ni un “que gane la mayoría”. Lo que
produce es un mapa de la conversación entre modelos: en qué están de acuerdo (consenso, que se trata como mayor
confianza), dónde se contradicen, qué cubrió solo alguno, qué ideas únicas aportó cada uno y qué puntos ciegos no
tocó ninguno (OpenRouter).
El resultado que viaja entre el juez y el sintetizador tiene esta pinta:
{
"status": "ok",
"analysis": {
"consensus": ["..."],
"contradictions": [
{ "topic": "...", "stances": [{ "model": "...", "stance": "..." }] }
],
"partial_coverage": [{ "models": ["..."], "point": "..." }],
"unique_insights": [{ "model": "...", "insight": "..." }],
"blind_spots": ["..."]
},
"responses": [{ "model": "...", "content": "..." }]
}
Ese analysis es el oro del asunto. No te quedas con cuatro párrafos sueltos para que tú los compares a ojo,
sino con un diagnóstico ya masticado: aquí coinciden, aquí chocan, esto no lo vio nadie.
💡 Si solo te llevas una cosa de esta sección: Fusion no es votación por mayoría. Es un análisis estructurado
de consenso y contradicciones que un modelo usa para redactar la respuesta final.
Un detalle que evita sustos: la búsqueda web está activada en las llamadas del panel y del juez, nunca en la
síntesis final. Para cuando tu modelo escribe la respuesta, ya tiene el análisis fresco y estructurado en la
mano (OpenRouter). Y por si te lo preguntas:
hay protección contra recursión, así que ningún modelo del panel puede volver a invocar Fusion y montarte una
matrioska de comités infinitos.
Por cierto, en algún hilo que circula por ahí se habla de que el panel tiene “bash” habilitado. Cuidado con eso:
en la documentación y en el blog oficiales lo que aparece es búsqueda web y lectura de páginas (web search y
web fetch), no bash. Si vas a contarlo, mejor no propagar el dato hasta tener confirmación directa.
Si te enganchan estas tripas de cómo deliberan los modelos entre sí, cada domingo desmenuzamos lo que va cambiando en la adopción de IA al programar. Ya somos +6.700, gratis desde 2018.
Apúntate gratis →Las dos formas de llamar a Fusion ¶
Hay dos formas de llamar a Fusion desde la API: el alias de modelo openrouter/fusion, que inyecta la
herramienta solo, y la herramienta de servidor openrouter:fusion declarada en el array de tools, que te da más
control. OpenRouter ha sido listo y la elección depende de cuánto control quieras.
La primera es el alias de modelo. Lo tratas como si fuera un modelo cualquiera y la herramienta se inyecta
sola:
{
"model": "openrouter/fusion",
"messages": [
{ "role": "user", "content": "¿Cuáles son los argumentos a favor y en contra de un impuesto al carbono?" }
]
}
Esto es lo vendible: para tu código parece una llamada normal. Sencillo de adoptar, cero fricción.
La segunda es la herramienta de servidor explícita. Eliges tu propio modelo exterior y puedes combinar Fusion
con otras herramientas:
{
"model": "openrouter/fusion",
"messages": [{ "role": "user", "content": "..." }],
"tools": [{ "type": "openrouter:fusion" }]
}
En ambos casos el modelo decide cuándo activar Fusion. Para prompts triviales no se molesta en montar el comité y
te responde directo. Si quieres forzarlo a deliberar en cada petición, le pones tool_choice: "required"
(OpenRouter).
¿Y si no te gusta el panel que trae por defecto? El preset Quality usa Claude Opus, GPT y Gemini Pro, que es
potente pero caro. Puedes cambiarlo con un bloque parameters:
{
"tools": [
{
"type": "openrouter:fusion",
"parameters": {
"analysis_models": [
"google/gemini-flash-latest",
"deepseek/deepseek-v3.2-20251201",
"moonshotai/kimi-latest"
],
"model": "anthropic/claude-opus-latest"
}
}
]
}
En ese bloque, analysis_models es el panel (admite de 1 a 8 modelos) y model es el juez que sintetiza el
análisis. También puedes tocar el número máximo de pasos de búsqueda, los tokens de salida o la temperatura
(OpenRouter). Vamos, que el comité te lo
montas a tu gusto.
¿Qué dicen los benchmarks de DRACO? ¶
OpenRouter probó Fusion con DRACO, un benchmark de investigación profunda de Perplexity con 100 tareas repartidas
en 10 dominios (investigación académica, finanzas, derecho, medicina, tecnología, diseño UX y unos cuantos más).
Cada tarea trae una rúbrica de unos 39 criterios ponderados que miden exactitud factual, profundidad,
presentación y calidad de las citas
(OpenRouter).
Aquí están los resultados que publicaron:
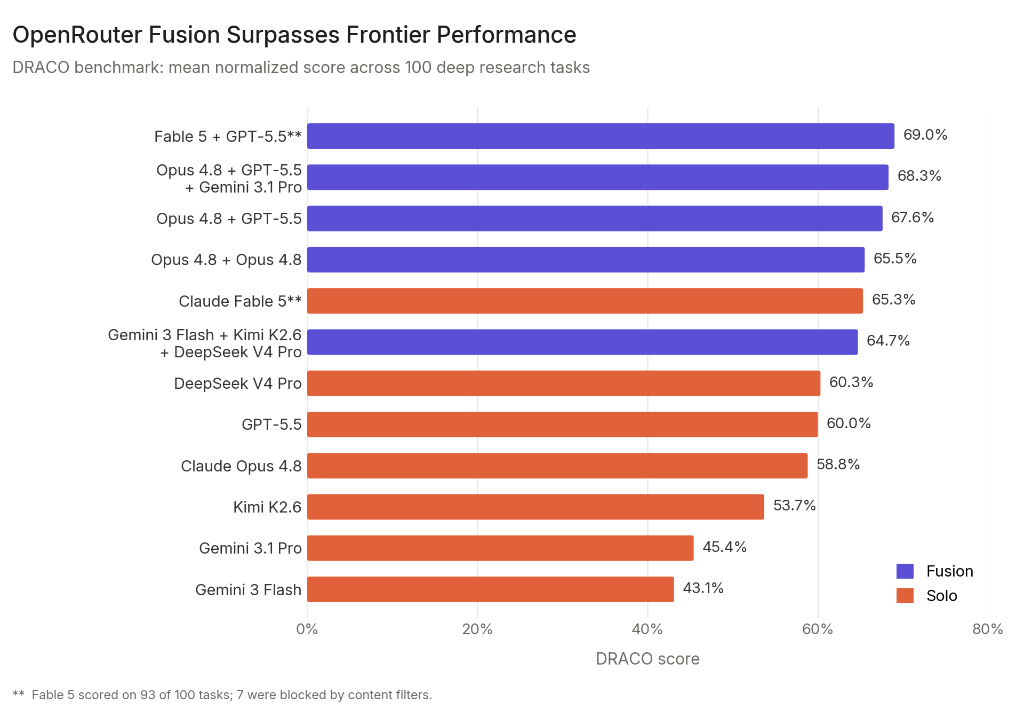
| Tipo | Modelo(s) | Puntuación |
|---|---|---|
| Fusion | Fable 5 + GPT-5.5 (sintetiza Opus 4.8) | 69,0% |
| Fusion | Opus 4.8 + GPT-5.5 + Gemini 3.1 Pro (sintetiza Opus 4.8) | 68,3% |
| Fusion | Opus 4.8 + GPT-5.5 (sintetiza Opus 4.8) | 67,6% |
| Fusion | Opus 4.8 + Opus 4.8 (sintetiza Opus 4.8) | 65,5% |
| Solo | Claude Fable 5 | 65,3% |
| Fusion | Gemini 3 Flash + Kimi K2.6 + DeepSeek V4 Pro | 64,7% |
| Solo | DeepSeek V4 Pro | 60,3% |
| Solo | GPT-5.5 | 60,0% |
| Solo | Claude Opus 4.8 | 58,8% |
| Solo | Kimi K2.6 | 53,7% |
| Solo | Gemini 3.1 Pro | 45,4% |
| Solo | Gemini 3 Flash | 43,1% |
Tres lecturas saltan a la vista. La combinación Fable 5 + GPT-5.5 sintetizada por Opus 4.8 llegó al 69,0%, por
encima de Claude Fable 5 en solitario (65,3%), que ya es el modelo
público más capaz de Anthropic. Un panel barato de Gemini 3 Flash, Kimi K2.6 y DeepSeek V4 Pro alcanzó 64,7%,
batiendo a GPT-5.5 y a Opus 4.8 en solitario, y se quedó a menos de
un punto de Fable 5 a la mitad de coste
(OpenRouter).
Y la tercera, que para mí es la más reveladora: cuando juntaron Opus 4.8 consigo mismo como panel de dos, con
Opus 4.8 también de juez, subió de 58,8% a 65,5%. Un salto de 6,7 puntos sin meter ningún modelo distinto. Eso
sugiere que buena parte de la mejora no viene de la diversidad de arquitecturas, sino del propio paso de
síntesis: ejecutar el mismo prompt dos veces produce caminos de razonamiento distintos
(OpenRouter).
Ahora la parte honesta, que es la que nos gusta en Web Reactiva. Fable 5 no completó 7 de las 100 tareas
porque sus filtros de contenido las bloquearon. OpenRouter decidió no recurrir a Opus 4.8 para esas tareas, así
que el resultado de Fable refleja 93 tareas, no 100. Lo reconocen en la propia tabla: la comparación directa
contra modelos que sí terminaron las 100 no es del todo limpia
(OpenRouter).
⚠️ Estos números son vendor-reported, publicados por la propia OpenRouter. Además usaron Gemini 3.1 Pro Preview
como juez en lugar del modelo del paper original, así que sus puntuaciones no son comparables uno a uno con
DRACO. Léelos como una señal de dirección, no como verdad absoluta.
Hay otro matiz metodológico que dice mucho de lo verde que está esto. Al dar búsqueda web al panel, los modelos
empezaron a encontrar la propia rúbrica de DRACO en internet. No era trampa intencionada, pero contaminaba el
resultado. Lo resolvieron excluyendo esas URLs de la búsqueda
(OpenRouter). Detalle pequeño, lección grande:
cuando das internet a un modelo para evaluarlo, vigila que no se esté chivando a sí mismo las respuestas.
¿Cuánto cuesta montar un comité de modelos? ¶
Caro. No nos engañemos. Fusion ejecuta N llamadas del panel más una del juez, además de tu petición normal. Con
el panel de 3 modelos por defecto, la documentación dice que esperes alrededor de 4–5× el coste de una
completion simple sobre el mismo prompt, y que ese coste escala de forma lineal con el tamaño del panel
(OpenRouter).
Traducido: cada vez que convocas el comité, pagas a todos los que se sientan a la mesa más al que toma el acta.
Tiene toda la lógica del mundo, pero conviene tenerlo presente antes de enchufar Fusion a un bucle que se dispara
mil veces al día.
Esto enlaza con algo que ya tratamos a fondo en cómo gastar menos eligiendo el modelo correcto en GitHub
Copilot: la disciplina de coste no desaparece con la IA, se
traslada. Antes decidías qué modelo usar por tarea. Ahora, además, decides cuándo merece la pena pagar por un
tribunal entero y cuándo te basta con mandar al becario barato a por el JSON.
🛡️ Antes de meter Fusion en producción, calcula el multiplicador de coste real con tu panel y tu volumen. Un
comité de cinco modelos en un endpoint de alto tráfico se come el presupuesto sin avisar.
Cuándo merece la pena Fusion (y cuándo no) ¶
Aquí es donde Fusion pasa de curiosidad de Twitter a herramienta útil. La regla general es sencilla: Fusion
vale cuando equivocarte cuesta más que pagar varias completions.
Donde tiene sentido tirar del comité:
- Revisión de specs, PRDs y decisiones técnicas. Varios modelos detectan huecos distintos en un mismo
documento. - Análisis de arquitectura. Pedir consenso, contradicciones y puntos ciegos sobre un diseño es justo lo que
hace un buen design review humano. - Comparativas de librerías, frameworks o proveedores. Fusion está pensado para sintetizar perspectivas, y
estos “compara y contrasta” le vienen al pelo. - Revisión de prompts críticos. No para cada prompt, sino para los que van a alimentar agentes o
automatizaciones donde un fallo se multiplica. - Benchmark privado de modelos. Lanzas tus diez prompts reales y dejas de decidir por la portada de Twitter
del día.
Donde yo no lo usaría sin pensarlo dos veces:
- Bucles de programación largos, donde mezclar estilos de varios modelos introduce inconsistencias en el código.
- Generación masiva y tareas baratas o repetitivas, porque el multiplicador de coste no compensa.
- Respuestas que exigen JSON estricto o formatos muy cerrados.
- Chat en tiempo real, donde la latencia de varias llamadas en serie se nota.
Si lo piensas, es el mismo principio que repetimos cuando salió GPT-5.5 frente a Opus
4.7: la mejor estrategia sigue siendo multimodelo, no monomodelo.
Fusion no contradice esa idea, la lleva un paso más allá y la automatiza.
Decidir cuándo sacas la artillería pesada y cuándo basta con un modelo barato es media batalla con la IA. Cada semana seleccionamos 12 recursos sobre productividad y herramientas, y los +6.700 que ya estamos dentro aportamos lo que vamos probando.
Quiero esa dinamita 🧨Cómo encaja Fusion en tu flujo de trabajo ¶
Vamos a aterrizarlo con un caso concreto, que es como mejor se entiende. Imagina que tienes que decidir el stack
de autenticación de un proyecto nuevo y dudas entre tres enfoques.
El flujo manual de toda la vida sería: abres tres pestañas, pegas el mismo contexto tres veces, lees tres
respuestas largas, intentas acordarte de qué dijo cada una y, con suerte, sacas una conclusión antes de que se te
enfríe el café.
Con Fusion, ese trabajo de comparar lo hace el juez por ti. Tú formulas la pregunta una vez, eliges si quieres el
panel caro o el barato, y recibes una respuesta que ya viene con el “aquí los tres coinciden, aquí Opus discrepa
de GPT, esto no lo mencionó ninguno”. El paso de leer en diagonal tres tochos y cruzarlos a mano desaparece.
Esto es relevante para cualquiera que ya esté montando agentes. Si usas Hermes
Agent o cualquier herramienta que apunte a OpenRouter, puedes
invocar Fusion como una herramienta más dentro del flujo agéntico, no solo desde el playground bonito para la
foto de LinkedIn. Y si lo tuyo es algo más ligero como resumir contenido desde la
terminal, el patrón es el mismo: OpenRouter como pasarela, y tú
decidiendo el nivel de artillería según la tarea.
Una recomendación práctica que ya defendíamos antes de Fusion: revisa con un modelo distinto al que ejecutó la
tarea. Dos perspectivas pillan más sesgos que una. Fusion convierte ese consejo en infraestructura, porque el
panel es exactamente eso, varias perspectivas obligadas a mirar el mismo problema.
Cinco casos de uso donde Fusion paga su precio ¶
Las razones para usar Fusion no son abstractas. Son situaciones que reconoces porque ya las has sufrido. Te dejo
cinco donde el multiplicador de coste se justifica solo.
1. Decisiones de arquitectura con coste de reversión alto.
Elegir entre monolito modular y microservicios, decidir el modelo de datos de un sistema de eventos o fijar la
estrategia de caché son decisiones que arrastras durante años. Aquí un solo modelo te da una opinión segura de sí
misma; un panel te da el desacuerdo, que es justo lo que necesitas ver antes de comprometerte. Un prompt tipo
“compara estos tres enfoques de arquitectura para X, señala los puntos ciegos de cada uno y dónde discreparían
los expertos” exprime exactamente lo que Fusion hace bien.
2. Due diligence de una dependencia antes de meterla en producción.
Vas a añadir una librería nueva al package.json y quieres saber si te vas a arrepentir en seis meses:
mantenimiento, licencia, alternativas, deuda que arrastra. Un panel con búsqueda web activada cruza fuentes
recientes y te marca lo que un modelo solo habría pasado por alto. La parte de blind spots del análisis es
oro puro en este caso.
3. Revisión de una spec o un PRD antes de escribir una sola línea.
El momento más barato para encontrar un agujero en un proyecto es antes de empezarlo. Pasas el documento por
Fusion y el juez te devuelve qué entendieron igual todos los modelos (consenso), dónde interpretaron cosas
distintas (contradicciones) y qué requisito no contempló ninguno (punto ciego). Eso último, lo que nadie
mencionó, es la señal más valiosa: suele ser el agujero que te explota en la semana tres.
4. Comparativa honesta entre proveedores.
Hosting, autenticación, pasarela de pagos, proveedor de correo transaccional. Estas comparativas están plagadas
de contenido SEO interesado y de modelos que repiten el marketing del fabricante de turno. Un panel que contrasta
varias perspectivas y marca dónde se contradicen entre ellas te da una foto menos sesgada que preguntarle a un
único modelo entrenado vete a saber con qué.
5. Validar un prompt que va a vivir dentro de un agente.
Un prompt que ejecutas una vez no merece Fusion. Uno que va a dispararse diez mil veces dentro de una
automatización, sí. Antes de soltarlo, lo pasas por el comité para que detecte ambigüedades, casos límite y
supuestos no declarados. Pagas el comité una vez para ahorrarte mil ejecuciones torcidas.
Un ejemplo mínimo de cómo lanzarías el caso 1 forzando la deliberación:
{
"model": "openrouter/fusion",
"messages": [
{
"role": "user",
"content": "Compara monolito modular frente a microservicios para una API de facturación con picos de
tráfico mensuales. Señala consenso, contradicciones entre enfoques y los puntos ciegos que nadie suele
mencionar."
}
],
"tool_choice": "required"
}
🔑 El hilo común de los cinco casos: equivocarte sale más caro que pagar varias completions. Si no se cumple
esa condición, no convoques al comité.
Lo que tienen en común estos casos y lo que vimos en cómo gastar menos eligiendo el modelo
correcto es la misma idea de fondo: aplicas artillería
pesada solo donde el riesgo lo pide. Para lo demás, un modelo barato y a otra cosa.
El cambio real: de elegir modelo a diseñar paneles ¶
El cambio de fondo que trae Fusion es este: el trabajo del developer se mueve de elegir un modelo a diseñar
un equipo de modelos. Y aquí llega lo que de verdad me parece importante, más allá de la herramienta concreta.
Durante el último año, la pregunta del developer ha sido siempre la misma: ¿qué modelo uso? Opus o GPT, Sonnet o
Gemini, el caro o el barato. Una decisión binaria, de andar por casa.
Fusion apunta a que la siguiente capa no va de elegir el mejor modelo, sino de diseñar equipos de modelos.
Aparecen términos nuevos que conviene ir colocando en tu vocabulario: paneles de modelos, jurados de IA,
deliberación multimodelo, capa de síntesis, modelo juez, consenso frente a contradicción.
Es el mismo salto que dimos con los humanos cuando dejamos de fiarnos de un solo experto y montamos comités,
revisiones por pares y design reviews. La diversidad de perspectivas mejora el resultado en problemas complejos.
OpenRouter resume su hallazgo en cuatro palabras: “Panels consistently outperform individual models”, y dice
basarse en la misma analogía con el rendimiento de los equipos humanos
(OpenRouter).
💡 El ángulo potente no es “OpenRouter ha creado un modelo que supera a los frontier”. Eso es confeti. El
ángulo bueno es: el trabajo fino ya no es elegir cerebro, sino orquestar varios cerebros y decidir quién hace de
juez.
Conviene no perder la cabeza con el hype. La conversación pública sobre Fusion todavía está verde: repetición del
anuncio, algún hilo escéptico en foros pidiendo ver la factura, una petición en GitHub para configurar los
presets desde la terminal sin tocar la API a mano, y pocos tests independientes serios. La dirección parece
sólida, pero los datos duros e imparciales aún no han llegado.
Y hay una pega de fondo que no me callo: estás construyendo encima de un intermediario. Ganas comodidad y
amplitud de modelos, sí, pero también dependes de su disponibilidad, sus términos de servicio y su criterio sobre
qué panel se ejecuta por debajo. Si no sabes exactamente qué modelos componen tu Fusion, estás comprando magia
con etiqueta de ingeniería. Mídelo tú, con tus prompts.
Porque al final la conclusión es la de siempre por aquí. Fusion no sustituye tu criterio. Lo desplaza un nivel
hacia arriba. Antes decidías qué modelo. Ahora decides cuándo montar el tribunal y a quién sientas en él.
La solución a que una IA se equivoque era, claro, convocar una reunión. La humanidad nunca falla en sus clásicos.
😉
Preguntas frecuentes sobre OpenRouter Fusion ¶
¿Qué es OpenRouter Fusion? ¶
Fusion es una capa de orquestación de OpenRouter que envía tu prompt a varios modelos en paralelo, hace que un
modelo juez compare sus respuestas y genera una única respuesta final basada en ese análisis. Se presentó el 12
de junio de 2026 y no es un modelo entrenado desde cero, sino un flujo de trabajo convertido en llamada de API.
¿Fusion es un modelo nuevo? ¶
No. Fusion combina modelos que ya existen (como Opus 4.8, GPT-5.5 o Gemini) en un panel coordinado. La novedad
está en la orquestación y la síntesis, no en un nuevo cerebro entrenado por OpenRouter.
¿Fusion funciona por votación de mayoría? ¶
No. El modelo juez no hace una media ni elige la respuesta más repetida. Produce un análisis estructurado que
identifica consenso, contradicciones, cobertura parcial, ideas únicas y puntos ciegos, y un modelo sintetizador
escribe la respuesta final a partir de ese diagnóstico.
¿Cómo se llama a Fusion desde la API? ¶
De dos formas: con el alias model: "openrouter/fusion", que inyecta la herramienta de forma automática, o
declarando la herramienta de servidor { "type": "openrouter:fusion" } en el array de tools para tener más
control. En ambos casos el modelo decide cuándo activarla.
¿Cuánto cuesta usar Fusion? ¶
Con el panel de 3 modelos por defecto, OpenRouter estima alrededor de 4–5× el coste de una completion simple
sobre el mismo prompt, porque ejecuta N llamadas del panel más una del juez. El coste escala de forma lineal con
el número de modelos del panel.
¿Qué puntuación sacó Fusion en el benchmark DRACO? ¶
La combinación Fable 5 + GPT-5.5 sintetizada por Opus 4.8 alcanzó 69,0%, frente al 65,3% de Fable 5 en solitario.
Un panel barato de Gemini 3 Flash, Kimi K2.6 y DeepSeek V4 Pro llegó a 64,7%, batiendo a GPT-5.5 y Opus 4.8 por
separado.
¿Son fiables esos benchmarks? ¶
Hay que leerlos con cautela. Son resultados publicados por la propia OpenRouter, Fable 5 no completó 7 de las 100
tareas por filtros de contenido, y usaron un modelo juez distinto al del paper original de DRACO, así que no son
comparables uno a uno con las cifras publicadas por Perplexity.
¿Puedo elegir qué modelos forman el panel? ¶
Sí. Con el bloque parameters defines analysis_models (el panel, de 1 a 8 modelos) y model (el juez que
sintetiza). Si no lo configuras, Fusion usa el preset Quality con Opus, GPT y Gemini Pro. Nada te impide montar un panel solo de open-weights: meter un GLM-5.2 como analista sale baratísimo frente al preset propietario.
¿Para qué casos de uso es ideal OpenRouter Fusion? ¶
Fusion brilla en decisiones de arquitectura con coste de reversión alto, due diligence de dependencias antes de
producción, revisión de specs y PRDs, comparativas honestas entre proveedores y validación de prompts que van a
vivir dentro de un agente. El patrón común es que un error sale más caro que pagar varias completions.
¿Para qué tareas no conviene usar Fusion? ¶
Para bucles de programación largos donde mezclar estilos introduce inconsistencias, para generación masiva o
tareas baratas y repetitivas, para respuestas que exigen JSON estricto y para chat en tiempo real, donde la
latencia de varias llamadas se nota.
¿Fusion sustituye al criterio del developer? ¶
No. Fusion automatiza el “pregunta a varios modelos y compara”, pero la decisión de cuándo merece la pena montar
el comité, qué modelos sentar en él y cómo interpretar el resultado sigue siendo tuya.
Fuentes ¶
- Surpassing Frontier Performance with Fusion — OpenRouter
Blog - Fusion Router — OpenRouter Docs
- Fusion Server Tool — OpenRouter Docs
- Anuncio de Fusion en X (@OpenRouter)
🧨 Última oprtunidad para recibir la dinamita que mereces sobre programación con IA el próximo domingo: Suscríbete gratis a Web Reactiva en https://webreactiva.com/newsletter


Escrito con la ayuda de la IA generativa de Claude, fuentes fidedignas y con un human in the loop:
Dani Primo.
12 recursos para developers cada domingo en tu bandeja de entrada
Además de una skill práctica bien explicada, trucos para mejorar tu futuro profesional y una pizquita de humor útil para el resto de la semana. Gratis.