SDD: qué es el Spec Driven Development y uso con IA
El Spec Driven Development (SDD) es una forma de programar con IA en la que escribes primero una especificación —un documento que describe qué debe hacer el software y cómo se comporta— y solo después dejas que el agente genere el código. La spec manda. El código es el resultado, no la fuente de verdad.
Suena bonito en una frase.
Pero a ti no te convence una frase, te convence el dolor que te ahorra.
Imagina que abres un repositorio que tu agente de IA generó hace tres semanas. Doscientos ficheros. Tests que pasan. Y tú, mirando la pantalla, sin tener ni idea de por qué hay tres servicios distintos para mandar un email ni cuál de ellos es el bueno.
Ese momento de “esto funciona y no sé por qué” es justo lo que el SDD intenta que no te pase.
En este artículo vas a encontrar:
- Qué es el SDD y de dónde viene (incluida la confusión con sus siglas)
- Qué problema concreto resuelve cuando programas con un agente
- Cómo escribir una spec que de verdad sirva, con plantilla incluida
- El flujo paso a paso, sin atarte a ninguna herramienta
- Cuándo usarlo, cuándo no, y cómo meterlo en un proyecto que ya está vivo
👉 Empecemos por lo más básico, que es donde más gente se lía.
¿Qué es el SDD (Spec Driven Development)? ¶
El SDD es una metodología de desarrollo donde una especificación formal y legible por máquina actúa como la única fuente de verdad del proyecto. De ella se derivan la implementación, los tests y la documentación (Wikipedia, Spec-driven development). Y esta filosofía de “describe el qué y deja que el sistema lo materialice” ya ha desbordado el código: hoy puedes hasta gestionar tu workspace de Notion como si fuera infraestructura, describiendo el estado final y dejando que se reconcilie solo.
En malandriner: escribes el “qué” antes que el “cómo”. Y el agente trabaja a partir de ese documento en lugar de adivinar lo que tienes en la cabeza.
Antes de seguir, una aclaración que te ahorra más de un malentendido. Las siglas SDD tienen dos vidas.
- Spec Driven Development: el método del que hablamos aquí, asociado a programar con agentes de IA.
- Software Design Document: el clásico documento de diseño técnico de toda la vida, ese PDF que nadie volvía a abrir.
No son lo mismo, aunque comparten ADN. Cuando alguien dice “SDD” hablando de Claude Code, Cursor o Codex, casi siempre se refiere al primero. En Cursor, de hecho, esa idea vive en su Plan Mode: lo aplicamos paso a paso en cómo trabajar con agentes de programación en Cursor.
La idea no es nueva, ojo.
Sus raíces se remontan a los flujos de trabajo de la NASA en los años sesenta y a los métodos formales que verificaban la lógica antes de escribir una línea. Se formalizó en el ámbito académico en 2004 como una síntesis entre Test Driven Development y Design by Contract, y ha vivido un renacimiento empujado por los agentes basados en modelos de lenguaje (Wikipedia, Spec-driven development).
O sea: la disciplina es vieja. Lo nuevo es quién escribe el código a partir de la spec.
¿Y en qué se diferencia esto del TDD o del BDD de toda la vida? En una frase: el TDD pone el test como red de seguridad y el BDD describe el comportamiento esperado, mientras que el SDD coloca la especificación completa como contrato que gobierna todo el desarrollo. No me extiendo aquí porque ya lo desmenucé en la comparativa TDD vs BDD vs SDD.
Y si te van los matices finos, existe una variante que mantiene la spec viva como artefacto y le añade normas y salvaguardas por encima: te lo cuento en qué es SPDD.
🔑 El cambio de mentalidad del SDD cabe en una idea: el código deja de ser el rey y pasa a ser el súbdito. La spec es la fuente de verdad; el código, lo que se genera a partir de ella.
¿Qué problema resuelve el SDD al programar con IA? ¶
El SDD resuelve el problema del muro. Ese punto en el que la IA ha generado tanto código tan rápido que ya nadie —ni tú ni el agente— sabe qué hace el sistema ni por qué. Es la factura diferida del vibe coding.
Y no es una sensación tuya, es un patrón medido.
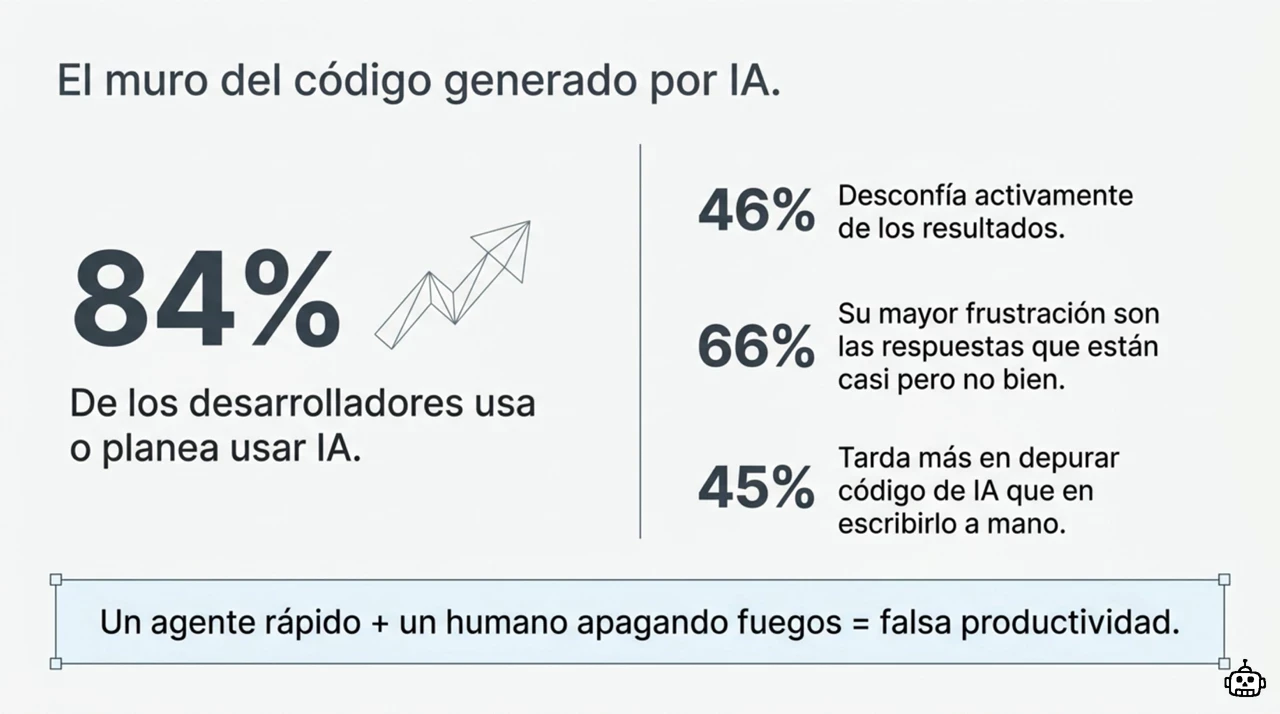
Según el Stack Overflow Developer Survey 2025, el 84% de los desarrolladores usa o planea usar herramientas de IA, frente al 76% del año anterior (Stack Overflow, Developer Survey 2025). La adopción está disparada. El problema es la otra cara de la moneda.
Ese mismo informe deja tres datos que escuecen:
- Solo el 29% confía en la precisión de lo que produce la IA, y un 46% desconfía de forma activa.
- La frustración número uno, citada por el 66% de los desarrolladores, son las respuestas que están “casi pero no” del todo bien.
- El 45% afirma que depurar código generado por IA le lleva más tiempo que haberlo escrito a mano.
Lee otra vez ese último.
Casi la mitad de la profesión tarda más en arreglar lo que escupe la IA que en teclearlo. Ahí no hay productividad que valga: hay un agente rápido y un humano apagando fuegos.
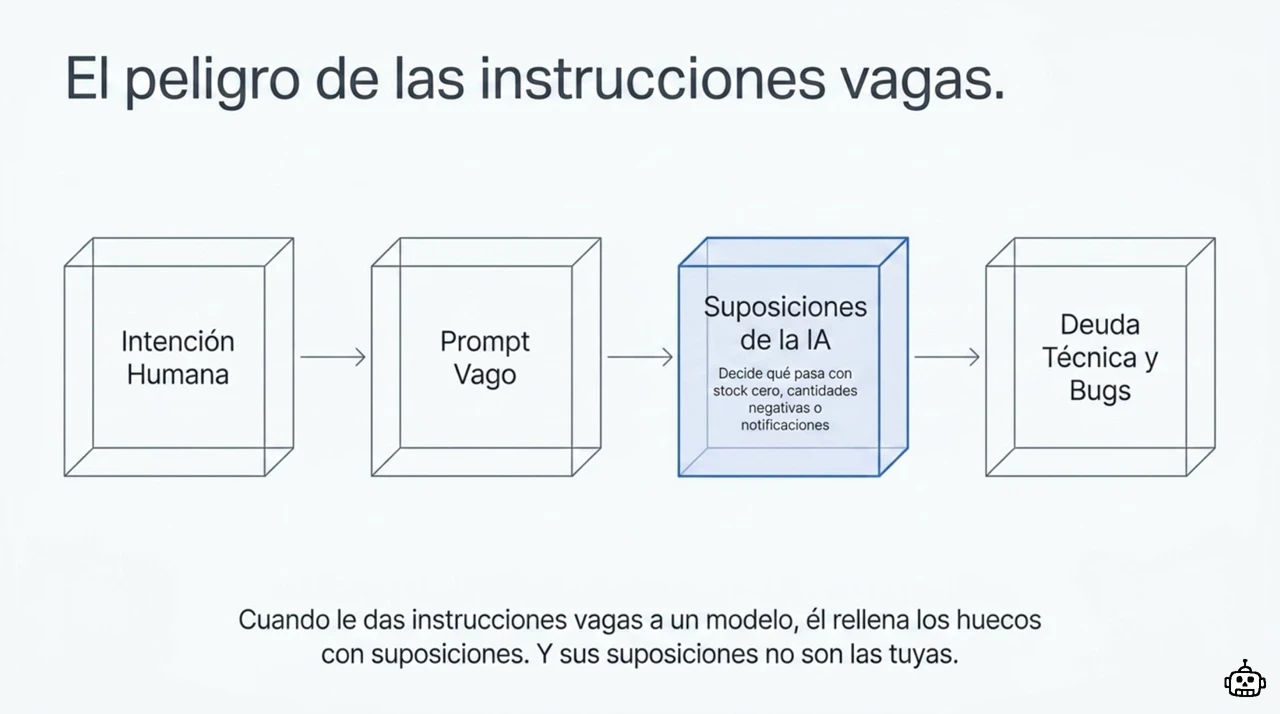
¿Por qué pasa esto? Porque cuando le das instrucciones vagas a un modelo, el modelo rellena los huecos con suposiciones. Y sus suposiciones no son las tuyas.
Pides “un sistema de pedidos” y el agente decide por su cuenta qué pasa si el stock es cero, si se permite pedir cantidades negativas, si hay que avisar por email. Tú nunca dijiste nada de eso. Él tampoco te preguntó.
El SDD mete una conversación obligatoria antes del código. ¿Qué casos hay que cubrir? ¿Qué debe pasar en los límites? ¿Qué reglas de negocio mandan? Esa conversación queda escrita.
Y un documento de veinte líneas resuelve en diez minutos lo que de otro modo descubrirías a base de tropezones en producción.
No es magia y tiene trampas, casi todas de mentalidad y no de comandos. Antes de adoptarlo conviene conocer los errores típicos con SDD, porque la mayoría de la gente arranca cometiendo los mismos.
💡 Si solo te llevas una cosa de esta sección: el SDD no hace a la IA más lista, te obliga a ti a pensar antes de pedir. Y pensar antes de pedir es justo lo que el chat improvisado se salta.

De la teoría a tu editor
El método SDD entero: cinco fases con un ejemplo guiado real
Si ese 45% que tarda más depurando código de IA que escribiéndolo te suena, el siguiente paso es el método completo: las cinco fases con un ejemplo guiado real y los prompts que uso para que el agente deje de improvisar.
Abrir la guía completa →Incluye autodiagnóstico · Acceso con Web Reactiva Premium
¿Cómo funciona el flujo SDD paso a paso? ¶
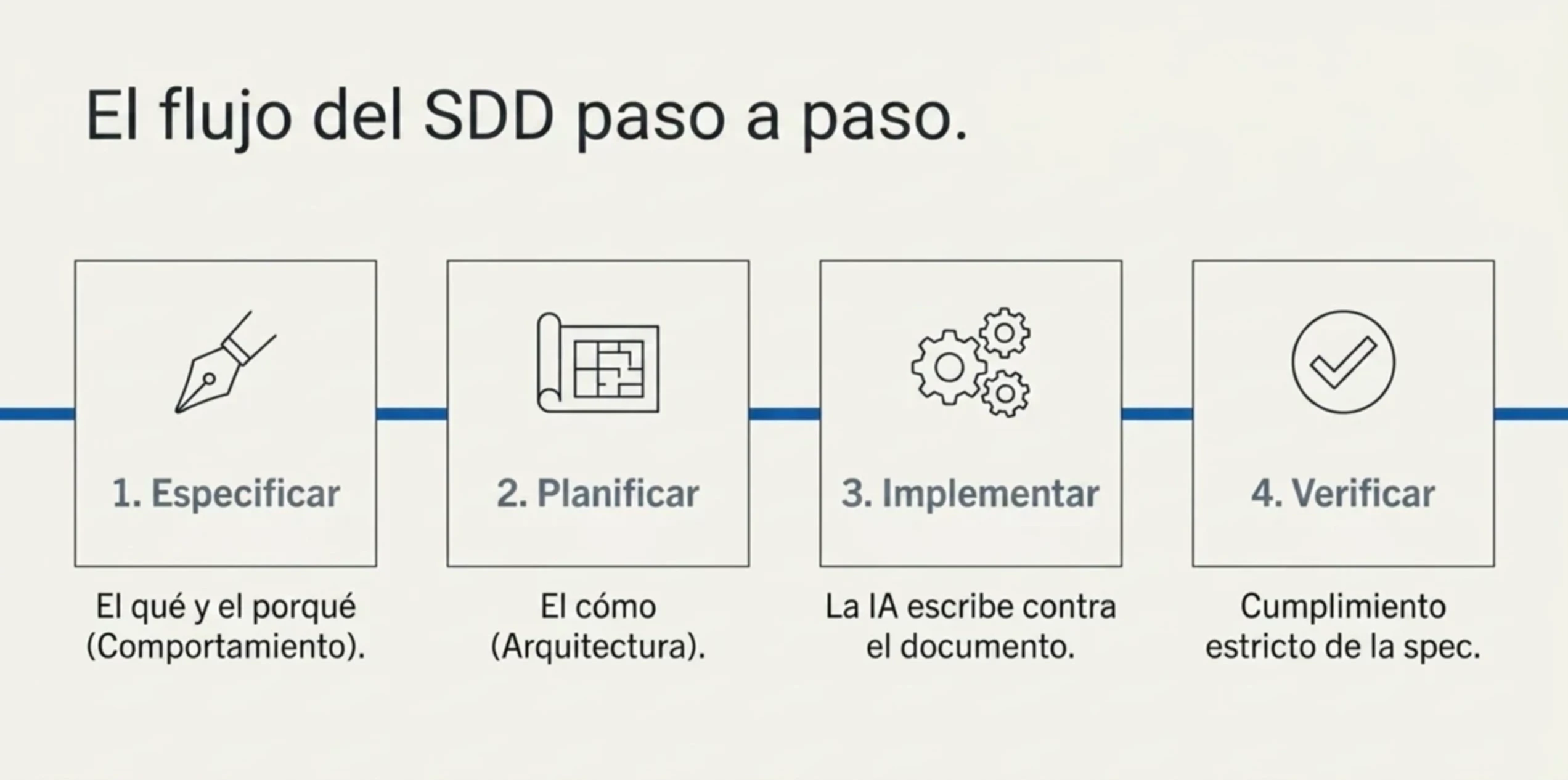
El flujo del SDD tiene cuatro fases conceptuales, las uses con la herramienta que las uses: especificar, planificar, implementar y verificar. Algunos frameworks las parten en más pasos —la guía de Spec Kit detalla seis comandos y la guía completa de OpenSpec trabaja con deltas—, pero por debajo siempre está este mismo esqueleto.
Te lo cuento con un ejemplo pequeño: añadir una función para exportar a CSV el listado de tareas de un proyecto. Nada de aplicaciones de juguete; algo que cualquiera ha tenido que picar alguna vez.
1. Especificar (el qué y el porqué). Aquí no hablas de código, hablas de comportamiento. Defines qué hace la función, qué entradas acepta y qué debe pasar en los casos raros.
2. Planificar (el cómo). Con la spec en la mano, traza el plan técnico: qué endpoint, qué librería de CSV, si hace falta paginar o usar streaming con miles de filas, dónde encajan los permisos. El plan es la traducción de la intención a decisiones de arquitectura.
3. Implementar. Ahora sí, el agente escribe el código. Y lo hace contra un documento que ya respondió las preguntas difíciles, no contra un prompt de tres líneas. Tú revisas, porque el código sigue siendo tuyo.
4. Verificar. Compruebas que lo construido cumple la spec. No “parece que va”, sino “cubre los escenarios que escribí”.
¿Lo ves? No hay nada aquí atado a una herramienta concreta. El flujo es el mismo tanto si lo haces a mano con un fichero markdown como si usas un framework que lo automatiza con slash commands.

¿Prefieres ver las cuatro fases funcionando antes que seguir leyendo?
Acabas de ver el flujo en teoría; este curso gratis te lo hace recorrer entero con OpenSpec sobre un proyecto real, en modo asistido, antes de aplicarlo a lo tuyo. Sin teoría de más.
Empezar el curso gratis →Ahora bien, todo esto se cae si la spec está mal escrita. Y ahí es donde casi todo el mundo tropieza.
Cómo escribir una spec útil para que la IA no improvise ¶
Una spec útil describe comportamiento, no implementación. Cierra los huecos donde el agente improvisaría. Si tu spec se puede leer y aún quedan preguntas sin respuesta, la IA las responderá por ti. Y no te van a gustar sus respuestas.
La regla madre es esta: escribe lo que debe ocurrir, sobre todo en los casos que preferirías no pensar.
Y aquí va una verdad incómoda que repite mucha gente con cicatrices: escribir la spec no es el trámite previo al trabajo, es el trabajo. John Pearson lo cuenta en The Spec Is the Hard Part: sus agentes implementan en un suspiro, pero él dedica el grueso del tiempo a llegar a una especificación lo bastante precisa. La claridad no aparece al principio por arte de magia; se gana explorando.
Estos son los cuatro principios que a mí me funcionan:
- Habla de qué, no de cómo. “El usuario puede exportar sus tareas” es spec. “Usa la librería X versión 2” es plan. No los mezcles.
- Sé explícito con entradas y salidas. Qué entra, qué sale, en qué formato. Lo que das por obvio es justo lo que el modelo malinterpreta.
- Nombra los casos límite. El borde raro que solo se da una vez al mes es donde la IA improvisa. Si lo escribes, deja de improvisar.
- Usa lenguaje verificable. Un GIVEN/WHEN/THEN o un criterio claro convierten la spec en algo que luego puedes comprobar. Una spec que no se puede verificar es una redacción.
Volvamos al ejemplo del CSV. Una spec mínima, escrita con esos principios, se vería así:
## Requirement: Exportar tareas a CSV
El usuario puede exportar las tareas de un proyecto a un fichero CSV.
### Scenario: Proyecto con tareas
- GIVEN un proyecto con al menos una tarea
- WHEN el usuario solicita la exportación
- THEN se genera un CSV con una fila por tarea
### Scenario: Proyecto vacío
- GIVEN un proyecto sin tareas
- WHEN el usuario solicita la exportación
- THEN se genera un CSV solo con la fila de cabeceras
Fíjate en el segundo escenario.
Ese “qué pasa si no hay tareas” es el hueco que un agente rellenaría a su antojo. La spec lo cierra antes de que llegue a ser un bug.
Y ojo con pasarte de frenada. Addy Osmani, en How to write a good spec for AI agents, defiende specs vivas, manejables y revisadas antes de generar código, no documentos kilométricos que le lanzas al agente como quien tira pienso a una cabra. Más restricciones buenas, no más texto.
Afinar specs hasta que el agente deje de improvisar es de esas cosas que se aprenden a base de roces. Cada domingo comparto lo que voy descubriendo programando con IA en proyectos reales, junto a +6.700 developers. Gratis, desde 2018.
Quiero esa dinamita 🧨
La spec mínima viable ¶
La spec mínima viable es la versión más corta que cierra la ambigüedad sin convertirse en burocracia. Ni un párrafo más, ni un caso límite menos. Su objetivo es que el agente no tenga que adivinar nada importante.
No necesitas un documento de treinta páginas. Necesitas cinco bloques.
Aquí tienes la plantilla que puedes copiar y reutilizar tal cual:
# [Nombre de la funcionalidad]
## Objetivo
Una o dos frases: qué problema resuelve y para quién.
## Comportamiento esperado
Los escenarios principales en formato GIVEN / WHEN / THEN.
## Casos límite
Qué pasa cuando algo falta, falla o se sale de lo normal.
## Criterios de aceptación
La lista de comprobaciones que separan "hecho" de "casi".
## Fuera de alcance
Lo que esta spec NO cubre, para que el agente no se invente trabajo.
El bloque que más gente se salta es el último.
“Fuera de alcance” es tu seguro contra el agente entusiasta que añade un sistema de notificaciones por email cuando tú solo querías exportar un CSV. Escribir lo que NO se hace vale tanto como escribir lo que sí.
🛡️ Si tu spec mínima viable cabe en una pantalla y responde “qué”, “qué pasa si” y “cómo sé que está bien”, ya estás por delante del 90% de la gente que le habla a la IA a las bravas.
¿Y cuánto detalle es demasiado? Llegamos al punto incómodo.
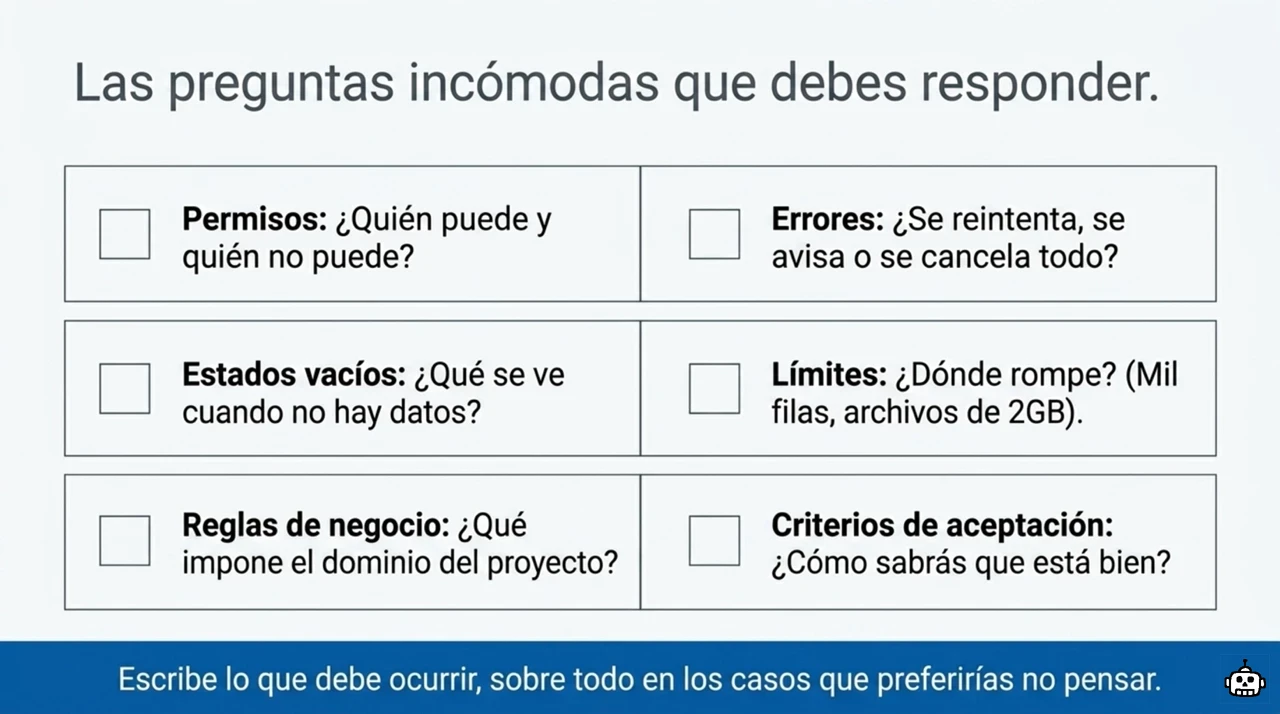
Las preguntas incómodas que una spec debe responder ¶
Una buena spec responde justo lo que tú evitarías pensar. Las decisiones aburridas, las de los bordes, las que dan pereza. Porque si tú no las contestas, las contesta el modelo, y ahí nacen la mitad de los bugs.
Antes de dar una spec por terminada, hazle este interrogatorio:
- Permisos. ¿Quién puede hacer esto? ¿Y quién no? ¿Qué pasa si lo intenta alguien sin permiso?
- Errores. ¿Qué ocurre cuando algo falla? ¿Se reintenta, se avisa, se cancela todo?
- Estados vacíos. ¿Qué ve el usuario cuando no hay datos? Un listado vacío no es lo mismo que un error.
- Límites. ¿Cuánto es demasiado? Mil filas, un millón, un fichero de 2 GB. ¿Dónde rompe?
- Reglas de negocio. ¿Qué manda el dominio? Las reglas que solo conoce quien lleva años en el proyecto.
- Criterios de aceptación. ¿Cómo sabrás que está bien? Si no puedes responder esto, aún no tienes spec.
No hace falta que todas tengan respuesta para todas las features. Una exportación a CSV quizá no necesite hablar de reintentos.
Pero el ejercicio de preguntártelas es lo que separa una spec de un deseo. No lo digo solo yo: en What Makes a Good LLM Spec, Ossature insiste en que una buena spec concreta decisiones, errores, restricciones, no-objetivos y ejemplos, porque ahí es justo donde el agente improvisa. Y recomienda auditar la spec en busca de ambigüedades antes de generar una sola línea.
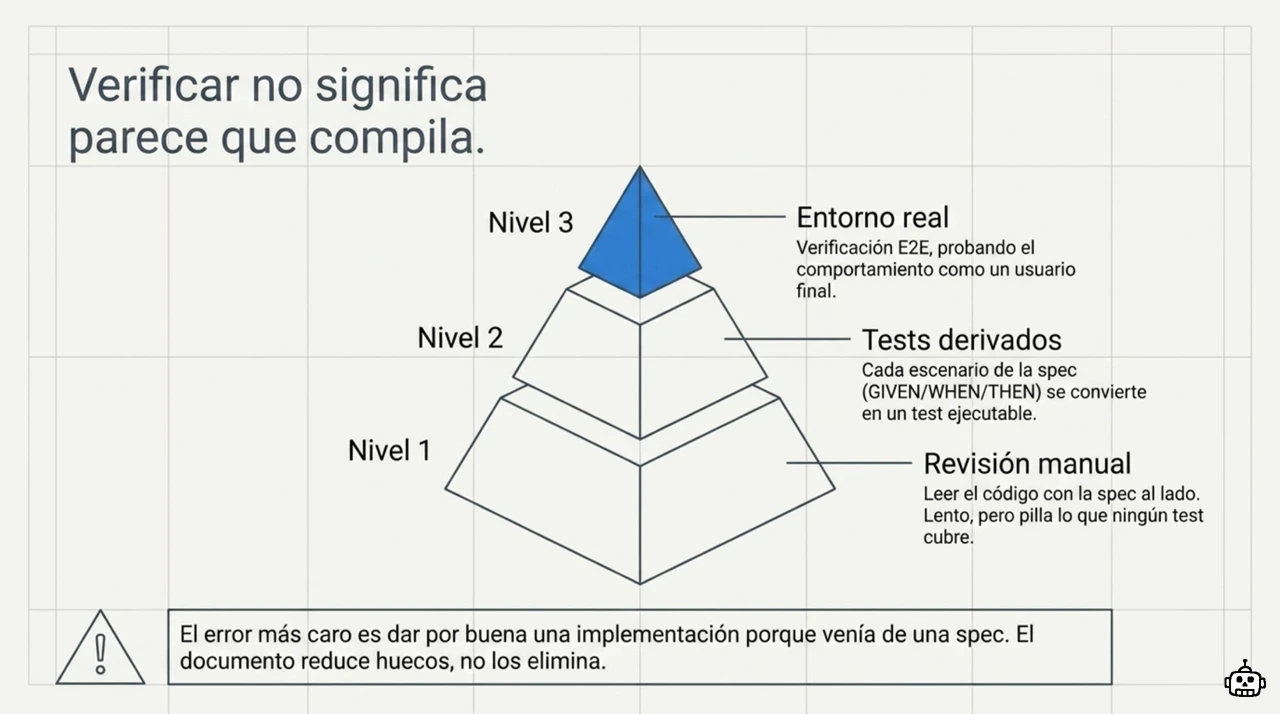
Verificar no es mirar si compila ¶
Verificar en SDD es comprobar que el código cumple los escenarios de la spec, no que arranca sin petar. Son dos cosas muy distintas, y confundirlas es lo que devuelve al vibe coding por la puerta de atrás.
“Compila.” “Los tests pasan.” “Parece que va.”
Ninguna de esas frases significa que el software hace lo que pediste. Significa que no se ha roto del todo. Es un listón demasiado bajo.
La verificación de verdad va escenario por escenario. Coges tu spec, lees el primer GIVEN/WHEN/THEN y compruebas que la implementación se comporta así. Y luego el siguiente. Y el del proyecto vacío, ese que el agente “resolvió” sin que tú lo vieras.
Hay tres niveles, de menos a más fiable:
- Revisión manual contra la spec. Lees el código con la spec al lado. Lento, pero pilla lo que ningún test cubre.
- Tests derivados de los escenarios. Cada escenario de la spec se convierte en un test. Aquí los criterios de aceptación dejan de ser texto y pasan a ser código que ejecutas.
- Verificación en entorno real. Pruebas el comportamiento de extremo a extremo, como lo vería un usuario.
⚠️ El error más caro es dar por buena una implementación “porque venía de una spec”. El documento reduce los huecos, no los elimina. Si la spec no contemplaba un caso, el código tampoco lo hará, y ningún test lo avisará.
El código sigue siendo tuyo. La spec te da un mapa para revisarlo, no una excusa para no hacerlo.
¿Qué necesitas para empezar con SDD? ¶
Para empezar necesitas, sobre todo, un framework que ponga orden en el flujo. Puedes hacer SDD a pelo con ficheros markdown y disciplina, pero un framework te da los comandos, las plantillas y la estructura para no reinventar el proceso cada vez.
Hoy hay dos referencias claras en el mundo open source.
La primera es OpenSpec, un framework con licencia MIT que implementa SDD con soporte para más de 25 herramientas: Claude Code, Cursor, Codex, OpenCode, Windsurf, Gemini CLI y compañía (GitHub, Fission-AI/OpenSpec). Requiere Node.js 20.19 o superior y trabaja con un enfoque de deltas: cada cambio vive en su propia carpeta con propuesta, especificaciones y tareas. Para bajarlo a tierra con un caso completo, tienes la guía completa de OpenSpec; y cuando quieras exprimirlo a fondo —arrancar sobre un proyecto legacy, montar tu propio esquema de artefactos y gastar menos tokens sin perder el control del agente—, lo desgrano en A fondo con OpenSpec.
La segunda es Spec Kit, el toolkit de GitHub para SDD. Soporta más de 30 agentes y organiza el trabajo en seis comandos: constitución, especificar, clarificar, planificar, tareas e implementar (GitHub, github/spec-kit). Tiene además un catálogo creciente de extensiones de la comunidad. Lo tienes explicado en la guía de Spec Kit.
¿Cuál elegir? Los dos son gratis, así que el coste de probar es tu tiempo —y si prefieres que alguien te lleve de la mano por un ciclo entero de OpenSpec antes de instalar nada, tienes el curso gratis de SDD con OpenSpec paso a paso. A grandes rasgos:
- OpenSpec brilla en brownfield: proyectos que ya existen y que quieres ir modificando con deltas.
- Spec Kit está más orientado a greenfield y a features grandes que arrancan de cero.
Más allá de la herramienta, lo que de verdad necesitas es el método metido en los dedos. Si prefieres aprenderlo de un tirón, con prompts concretos y outputs reales, tienes mi guía práctica de SDD paso a paso.
¿Cuándo NO usar SDD? ¶
El SDD no es para todo. Vendértelo como bala de plata sería hacerte un flaco favor. Hay escenarios donde escribir una spec antes de teclear es más estorbo que ayuda.
Estos son los casos donde yo lo dejo en el cajón:
- Prototipos desechables. Si vas a enseñar una idea en una demo y luego tirar el código, especificar es burocracia pura.
- Spikes técnicos. Cuando exploras si algo es viable, el objetivo es aprender, no construir bien. La spec llega después, si la cosa prospera.
- Scripts de usar y tirar. Ese one-liner que convierte un CSV no necesita un documento de diseño. Necesita ejecutarse y desaparecer.
- Cambios triviales. Corregir un typo, ajustar un color, subir una versión. Meter SDD ahí es matar moscas a cañonazos.
⚠️ Cuidado con el otro extremo: si aplicas SDD a todo, incluido lo que no lo necesita, lo conviertes en waterfall con otro nombre. No es un miedo mío: hay quien ya lo ha bautizado como “The Waterfall Strikes Back” y avisa de la sobreproducción de texto y la burocracia. La rigidez que mató a las metodologías rígidas también puede matar al SDD.
La regla que a mí me funciona es sencilla. Si el código va a vivir, a que lo lea otra persona o a que lo retomes dentro de seis meses, el SDD paga su precio con creces. Si nace para morir esta tarde, déjalo en paz. Ese mismo criterio —cuándo un framework como OpenSpec compensa y cuándo es matar moscas a cañonazos— lo desgrano en lo que nadie te cuenta de OpenSpec cuando lo usas en serio.
Decidir cuándo un método paga su precio y cuándo es pura burocracia es criterio que se afina con experiencia ajena. En la newsletter, +6.700 developers compartimos cómo está cambiando nuestro trabajo con la IA. Cada domingo, gratis.
Apúntate gratis →
Cómo introducir SDD en un proyecto que ya está vivo ¶
No reescribes nada. Aplicas SDD a la siguiente funcionalidad y dejas el resto del código como está. Esa es la respuesta corta para quien tiene un proyecto en producción, legacy o brownfield y no puede permitirse parar el mundo para documentarlo entero.
Casi nadie empieza desde cero. Y esa es la buena noticia, porque el SDD no exige una purga.
Estos son los pasos que funcionan en un proyecto vivo:
- Escribe un contexto mínimo del proyecto. Cuatro líneas sobre el dominio, las convenciones y las reglas que el agente no puede adivinar leyendo el código. Es la brújula.
- Aplica el método a la próxima feature. La que tengas ahora mismo entre manos. No al legacy entero.
- Especifica el cambio, no el pasado. Aquí el enfoque de deltas de OpenSpec encaja como un guante: describes qué cambia respecto a lo que ya hay, en vez de reescribir la realidad entera.
- Deja que el codebase actual sea el contexto. El agente lee lo que ya existe; tú solo especificas hacia dónde va.
¿El resultado? Cada funcionalidad nueva nace con su spec, y poco a poco el proyecto se va cubriendo por las zonas que tocas. Sin big bang, sin parón, sin reescrituras heroicas que nunca terminan.
Es lo opuesto a “vamos a documentarlo todo este sprint”. Eso no lo hace nadie, y tú lo sabes.
Ahora bien, sé honesto con la pega. En r/ExperiencedDevs la duda recurrente es cómo sostener esto en una empresa grande donde no todo el mundo adopta el flujo y el contexto vive disperso entre Jira, tickets y wikis a medio actualizar. Y tienen razón: el SDD no falla por la IA, falla por la entropía organizativa. Si nadie mantiene el contexto al día, la spec envejece tan mal como cualquier documentación. Es la misma trampa del context rot, la degradación del contexto que arrastra a tu agente cuando le das información vieja: una spec desactualizada es contexto podrido con otro nombre.
¿Qué opina la comunidad sobre el SDD? ¶
La comunidad está dividida, y esa división es sana. Los entusiastas ven velocidad y orden; los escépticos ven waterfall reciclado y promesas infladas. Los dos bandos tienen parte de razón, qué fastidio para quien quería una respuesta cómoda.
Te resumo los debates que más se repiten, para que te formes tu propio juicio.
El problema sigue siendo entender el problema
La crítica más afilada, que aparece una y otra vez en un hilo de r/programming, es que el SDD se vende como “escribe lo que quieres y la IA lo hace”, pero en proyectos reales muchas veces no sabes qué quieres hasta que prototipas, hablas con usuarios o chocas con el sistema que ya existe. De ahí sale un flujo con mucho sentido: prototipo desechable, aprendizaje, spec y, por fin, implementación de verdad. La spec no sustituye al descubrimiento.
El lenguaje natural es ambiguo; el código no
En Hacker News se repite una tesis incómoda: el código ya es una especificación ejecutable y bastante precisa, mientras que el lenguaje natural arrastra interpretaciones. Y en sistemas maduros nunca hay una spec completa, porque la realidad acumula bugs históricos, configuraciones raras y ese “pero en producción siempre ha funcionado así”. Hay quien va más lejos: si tu spec tiene que ser tan detallada como el código para ser fiable, quizá solo has inventado otro lenguaje de programación, pero en Markdown y con más teatro.
Estructura sí, sobrepeso no
En r/ClaudeCode hay quien cuenta que, con un flujo SDD y agentes que vigilan que no haya desvíos, resuelve buena parte de cada feature con mucha menos corrección manual. Pero ahí aparece el matiz: a veces resulta demasiado prescriptivo para el trabajo en solitario, aunque cunda en equipo. La comparación de r/ExperiencedDevs lo clava: el flujo libre es más rápido pero se ensucia; el spec-driven pesa más pero es más fiable. La lectura es que el SDD no gana por velocidad bruta, gana cuando recorta retrabajo, deriva y decisiones implícitas.
No todo el SDD es el mismo SDD
Aquí está el matiz más útil del debate. Birgitta Böckeler, en Martin Fowler, distingue tres niveles: spec-first (la spec guía una tarea), spec-anchored (la spec se conserva y evoluciona con la feature) y spec-as-source (la spec es el artefacto principal y el código se genera a partir de ella). Su conclusión es que el término aún está en movimiento y que muchas herramientas mezclan niveles sin aclarar cómo se mantiene la spec con el tiempo. Thoughtworks lo sitúa en “assess” dentro de su radar: interesante para explorar, pero todavía verde, opinado y muy dependiente del tipo de tarea, con el riesgo de generar specs largas que nadie revisa a gusto.
🔑 La postura más equilibrada: el SDD es un sistema de control excelente para agentes de IA, pero es peligroso venderlo como reemplazo del criterio técnico. Baja la deriva, persiste decisiones y crea criterios de aceptación. No elimina lo difícil: descubrir el dominio, elegir la arquitectura, decidir los trade-offs y validar con usuarios.
¿Qué he aprendido usando SDD en producción? ¶
Esto no lo he leído en un repo, lo he sufrido. Llevo meses aplicando SDD en un proyecto real en producción, con la gran mayoría del código generada por un agente. No es un experimento de laboratorio, es mi día a día.
Y por eso he visto dónde el método aporta y dónde estorba. Aquí van las cuatro lecciones que me habría gustado que alguien me contara antes.
1. Especifica el borde raro, no lo obvio
Las specs que más me han salvado son las que describen reglas de negocio y casos límite. Qué pasa cuando un dato falta, qué validaciones manda el dominio, qué ocurre en ese borde que solo se da una vez al mes.
Tener eso escrito antes de que el agente toque nada me ha evitado decenas de “esto no era lo que quería”.
2. No especifiques lo que no tiene ambigüedad
Las specs que me han sobrado son las que escribí por inercia para cosas evidentes. Detallar al milímetro un getter de tres líneas no me devolvió nada. Solo me robó tiempo y me dio la falsa sensación de estar haciéndolo bien.
Si no hay duda sobre qué debe hacer el código, la spec sobra.
3. La spec no te exime de revisar
Esta es la más incómoda. Hubo una temporada en la que confié de más, di por buena la implementación porque “venía de una spec” y me comí un bug que la propia spec no contemplaba.
El documento reduce los huecos, no los elimina. El código sigue siendo tuyo.
4. El verdadero ahorro llega al retomar
Con specs decentes puedo dejar un módulo dos semanas, volver, leer su carpeta de cambios y retomarlo en minutos. Antes eso me costaba una mañana de arqueología sobre mi propio código.
Ese ahorro, repetido una y otra vez, es la diferencia entre algo que avanza y algo que se atasca.
Te resumo la conversión: aplica SDD donde haya ambigüedad o donde el yo del futuro vaya a sufrir. En lo demás, ahórrate la ceremonia.
Del método a tu proyecto en producción
El ahorro de verdad llega al retomar: domina OpenSpec en tu código real
Si lo que más te ha sonado es volver a un módulo semanas después y retomarlo en minutos, ese es justo el terreno de OpenSpec. La guía a fondo te enseña a aplicarlo sobre código legacy, montar tu propio esquema de artefactos y gastar menos tokens sin perder el control del agente.
Ir a fondo con OpenSpec →Semáforo interactivo + prompt copiable · Acceso con Web Reactiva Premium
Y si todavía no estás en la newsletter de Web Reactiva, suscríbete: cada domingo te llega una skill práctica, trucos para tu futuro profesional y una pizca de humor para el resto de la semana.
TL;DR ¶
- 🧭 El SDD (Spec Driven Development) es escribir la especificación antes que el código y dejar que la IA construya a partir de ella: la spec es la fuente de verdad.
- 🤖 Resuelve el muro del vibe coding: el 45% de los desarrolladores tarda más en depurar código de IA que en escribirlo (Stack Overflow, Developer Survey 2025).
- 📝 Una spec útil describe comportamiento y casos límite, no implementación. La mínima viable cabe en una pantalla.
- 🔁 El flujo tiene cuatro fases agnósticas de herramienta: especificar, planificar, implementar y verificar. Y verificar no es mirar si compila.
- 🧰 Para empezar usa un framework open source como OpenSpec o Spec Kit, y aplícalo a la próxima feature aunque el proyecto ya esté vivo.
Preguntas frecuentes ¶
¿Qué significa SDD en programación? ¶
SDD significa Spec Driven Development, una metodología en la que escribes una especificación del software antes de generar el código y la usas como fuente de verdad para implementar, probar y documentar. Cuidado: las mismas siglas también designan el clásico Software Design Document, que es otra cosa.
¿Qué es una spec en Spec Driven Development? ¶
Una spec es un documento que describe qué debe hacer el software y cómo se comporta, incluidos los casos límite, escrito antes de programar. No es documentación retrospectiva: es el contrato que el agente de IA lee para planificar, implementar y validar el código.
¿Cómo se escribe una spec para que la IA no improvise? ¶
Describe comportamiento y no implementación, sé explícito con entradas y salidas, nombra los casos límite y usa lenguaje verificable como GIVEN/WHEN/THEN. La clave es responder de antemano las preguntas que, si no contestas tú, contestará el modelo a su manera.
¿SDD es lo contrario del vibe coding? ¶
Sí. El vibe coding improvisa pidiéndole cosas a la IA sobre la marcha y corrigiendo después; el SDD define de antemano qué quieres para que el agente no rellene los huecos con suposiciones suyas. Uno apuesta por la velocidad inmediata, el otro por la previsibilidad.
¿Qué debe responder una buena especificación? ¶
Una buena spec responde las preguntas incómodas: permisos, manejo de errores, estados vacíos, límites, reglas de negocio y criterios de aceptación. Si no puedes decir cómo sabrás que la funcionalidad está bien, todavía no tienes una spec.
¿Necesito una herramienta para hacer SDD? ¶
No es imprescindible: puedes hacer SDD con ficheros markdown y disciplina. Pero un framework como OpenSpec o Spec Kit te da comandos, plantillas y estructura, así que no tienes que reinventar el proceso en cada proyecto.
¿Se puede aplicar SDD a un proyecto que ya existe? ¶
Sí, y es lo habitual. No reescribes el código: aplicas el método a la siguiente funcionalidad y especificas el cambio, no el pasado. El enfoque de deltas de OpenSpec está pensado para eso, describiendo qué cambia en lugar de reescribir toda la especificación.
¿Cómo se verifica el código generado por IA en SDD? ¶
Verificas escenario por escenario contra la spec, no solo comprobando que compila. Conviertes los criterios de aceptación en tests, revisas los casos límite que el agente pudo resolver por su cuenta y pruebas el comportamiento de extremo a extremo.
¿SDD hace el desarrollo más lento? ¶
Al principio parece más lento porque añade un paso antes de teclear. Pero compensa cuando cuentas el tiempo que dejas de perder depurando código que “casi” funcionaba: el 66% de los desarrolladores cita esas respuestas “casi pero no” como su mayor frustración con la IA (Stack Overflow, Developer Survey 2025).
¿Qué framework de SDD es mejor para empezar? ¶
Si trabajas sobre un proyecto que ya existe, OpenSpec encaja mejor por su enfoque de deltas; si arrancas de cero o atacas features grandes, Spec Kit está más orientado a eso. Los dos son open source y gratis, así que prueba uno y cambia si no te convence.
Fuentes ¶
- OpenSpec — repositorio oficial (Fission-AI/OpenSpec)
- Spec Kit — repositorio oficial (github/spec-kit)
- Stack Overflow Developer Survey 2025 — sección de IA
- Spec-driven development (Wikipedia)
- Spec-driven development with AI (GitHub Blog)
- Understanding Spec-Driven Development: Kiro, spec-kit y Tessl (Birgitta Böckeler, martinfowler.com)
- Spec-driven development — Technology Radar (Thoughtworks)
- The Spec Is the Hard Part (John Pearson)
- Spec-Driven Development: The Waterfall Strikes Back (Marmelab)
- How to write a good spec for AI agents (Addy Osmani)
- What Makes a Good LLM Spec (Ossature)
- Spec-driven development doesn’t work if you’re too confused to write the spec (r/programming)
- Does the Spec Driven development actually work for you? (r/ClaudeCode)
- Free-form AI coding vs spec-driven AI workflows (r/ExperiencedDevs)
- Agentic, spec-driven development en proyectos no greenfield (r/ExperiencedDevs)
- Spec driven development doesn’t work if you’re too confused to write the spec (Hacker News)
🚀 ¿Tu siguiente paso para que esto deje de ser teoría? Recorre un ciclo completo de SDD con OpenSpec, gratis y paso a paso, en el curso de SDD con OpenSpec. Se aprende haciéndolo.


Escrito con la ayuda de la IA generativa de Claude, fuentes fidedignas y con un human in the loop:
Dani Primo.
12 recursos para developers cada domingo en tu bandeja de entrada
Además de una skill práctica bien explicada, trucos para mejorar tu futuro profesional y una pizquita de humor útil para el resto de la semana. Gratis.