Oh My OpenCode: un equipo de agentes IA programando por ti desde el terminal
Si vives en el terminal, el nombre te sonará. Oh My Zsh transformó la experiencia de usar la línea de comandos con plugins, temas y configuraciones que hacían del terminal un lugar más habitable. Pues alguien ha tenido la misma idea, pero aplicada a los agentes de IA que escriben código.
Se llama OhMyOpenCode y su planteamiento es tan ambicioso como suena: coger el CLI de OpenCode y convertirlo en un sistema de orquestación donde múltiples modelos de IA trabajan juntos como si fueran un equipo de desarrollo.
No uno. Varios. Cada uno con su especialidad.
En este artículo vamos a ver qué es, cómo se instala, cómo funciona su sistema de agentes y por qué puede cambiar tu forma de trabajar con IA desde el terminal. Lo que vas a leer aquí sale de la documentación oficial del proyecto, del código fuente de los prompts de cada agente y de la experiencia real de quienes ya lo están usando.
Esto es lo que vamos a ver:
- Qué problema resuelve Oh My OpenCode
- Cómo se instala paso a paso
- Qué agentes tiene y para qué sirve cada uno (con detalles de sus prompts internos)
- Los dos modos de trabajo: Ultrawork y Prometheus
- El sistema de categorías y skills
- Las funcionalidades que marcan la diferencia: hooks, LSP, MCPs y más
- Configuración, costes y consejos prácticos
🧨 Este post ha sido creado con ayuda de Claude. OhMyOpenCode es un ecosistema vivo en plena ebullición y cambiante, con lo que la documentación debe ajustarse constantemente. Ponte siempre al día en su repositorio oficial y sigue las recomendaciones de la comunidad creada por YeonGyu-Kim.
El problema: un solo cerebro no es suficiente ¶
Las herramientas de IA para programar que usamos hoy, ya sean Cursor, Windsurf o los agentes CLI habituales, comparten una limitación: te obligan a trabajar con un solo modelo. Eliges Claude, eliges GPT y con ese cerebro te quedas para todo. Si quieres ver cómo se comparan estos agentes entre sí antes de dar el salto a la orquestación, revisa la comparativa de agentes de IA para programación en terminal.
Pero si has probado varios modelos sabes que cada uno tiene sus fortalezas y sus puntos débiles. Gemini es una bestia en frontend pero a veces alucina con lógica de backend compleja. Claude Opus es el rey del razonamiento general y el debugging pero quema tokens como si no hubiera mañana cuando lo usas para tareas sencillas. GPT tiene un talento especial para arquitectura pero se pone cabezota con el formateo.
¿El resultado? Acabas copiando y pegando código entre modelos para conseguir el mejor resultado posible. Un proceso manual, lento y que rompe cualquier flujo de trabajo. Pero más allá de qué modelo uses, el creador de Open Code insiste en que la calidad de tu código base importa más que la potencia del modelo.
Oh My OpenCode intenta resolver esto actuando como un orquestador. En lugar de tener un modelo que lo hace todo, convierte al agente principal en un jefe de ingeniería que delega tareas a sub-agentes especializados, cada uno funcionando sobre el modelo que mejor se adapta a la tarea. Esta misma idea —un coordinador que reparte cada tarea al modelo más capaz— es la que Sakana Fugu empaqueta como un solo modelo detrás de una API; la diferencia es que ahí no eres tú quien configura la orquestación, sino un coordinador entrenado que la decide por dentro.
🧠 La idea central es poderosa: no necesitas al modelo más caro para todo. Necesitas al modelo adecuado para cada tarea. Buscar en documentación no requiere la misma potencia que diseñar una arquitectura de microservicios.
Instalación paso a paso ¶
Lo primero que necesitas es tener OpenCode instalado en tu sistema. Es el CLI sobre el que funciona Oh My OpenCode como plugin. Si no lo tienes, puedes consultar su documentación en opencode.ai/docs.
Una vez tengas OpenCode, la instalación es directa:
# Instalación interactiva (recomendada)
bunx oh-my-opencode install
# Alternativa con npx
npx oh-my-opencode install
El instalador te hace varias preguntas sobre las suscripciones que tienes. Es importante responder con precisión porque de eso depende cómo se configuran los agentes:
- ¿Tienes suscripción a Claude Pro/Max? Si estás en el plan max20, la configuración aprovecha esos límites extendidos.
- ¿Tienes suscripción a OpenAI/ChatGPT Plus? Esto habilita GPT-5.3 Codex para el agente Oracle.
- ¿Vas a usar modelos de Gemini? Activa los agentes de frontend con Gemini 3 Pro.
- ¿Tienes GitHub Copilot? Funciona como proveedor de respaldo.
- ¿Tienes acceso a OpenCode Zen o Z.ai Coding Plan? Opciones adicionales para ampliar la cobertura de modelos.
Si prefieres un modo no interactivo, para CI/CD o porque ya sabes lo que necesitas:
# Ejemplo: tienes Claude Max y Gemini
bunx oh-my-opencode install --no-tui --claude=max20 --gemini=yes --copilot=no
# Ejemplo: solo tienes Claude
bunx oh-my-opencode install --no-tui --claude=yes --gemini=no --copilot=no
Después de la instalación, toca autenticar cada proveedor. Para Anthropic:
opencode auth login
# Selecciona Anthropic como proveedor
# Selecciona Claude Pro/Max como método
# Completa el flujo OAuth en el navegador
Para verificar que todo está bien puedes usar el comando de diagnóstico:
bunx oh-my-opencode doctor
Esto ejecuta más de 17 comprobaciones de salud del sistema: versión de OpenCode, registro del plugin, validez de las API keys, dependencias…
⚠️ Nota importante sobre Claude Code: el creador de Oh My OpenCode no recomienda utilizar la cuenta de Claude Code con estos agentes. Se han reportado problemas de bloqueo de cuentas al usar Claude Code como proveedor.
Instalar Oh My OpenCode es solo el primer paso, luego viene configurar agentes, proveedores y categorías. En la newsletter compartimos cada domingo 12 recursos sobre herramientas de IA, plantillas y productividad con +6.700 developers. Gratis desde 2018.
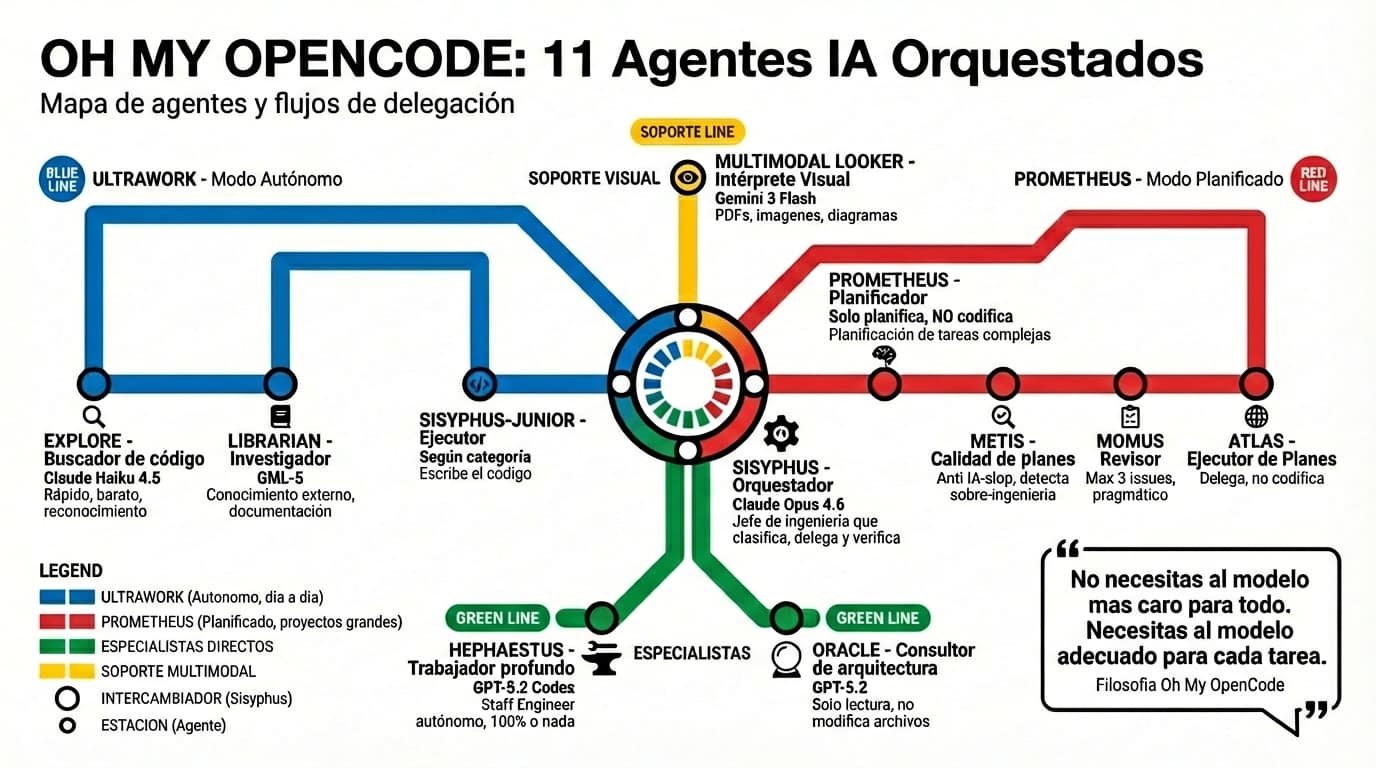
Quiero esa dinamita 🧨Los agentes: tu equipo de desarrollo virtual ¶
Aquí es donde la cosa se pone interesante. Oh My OpenCode no tiene un agente, tiene once. Cada uno con un rol específico, un modelo optimizado y permisos de herramientas concretos. Y lo más fascinante es ver cómo están construidos sus prompts internos: cada agente tiene una personalidad y unas reglas de comportamiento que condicionan su trabajo.
Puedes ver el código fuente completo de cada agente en github.com/code-yeongyu/oh-my-opencode/tree/dev/src/agents.
Sisyphus: el director de orquesta ¶

Funciona sobre Claude Opus 4.6 y es el cerebro del sistema. Tiene pensamiento extendido con un presupuesto de 32k tokens. Su nombre no es casual: como el personaje mitológico que empuja la roca cada día, Sisyphus empuja las tareas de desarrollo sin rendirse.
Lo que le diferencia de otros agentes no es solo que planifica y delega, sino cómo lo hace. Si buscas una alternativa con enfoque distinto, Agent Orchestrator de Composio orquesta agentes con worktrees aislados y un sistema de reacciones automáticas ante fallos de CI y code review. Su prompt interno establece una regla fundamental: “Tu código debe ser indistinguible del de un ingeniero senior”. Eso no es un adorno. Cada vez que Sisyphus recibe una petición, ejecuta un proceso de tres pasos antes de tocar una sola línea:
- Clasificación de la tarea: ¿Es trivial, explícita, exploratoria, abierta o ambigua? Cada tipo tiene un protocolo diferente.
- Verificación de la delegación: Antes de trabajar, se pregunta si existe un agente especializado más adecuado. Su sesgo por defecto es delegar. Solo trabaja él si la tarea es extremadamente simple.
- Validación de suposiciones: Comprueba si tiene información implícita que pueda afectar al resultado.
Cada delegación que hace Sisyphus debe incluir seis secciones obligatorias: la tarea concreta, el resultado esperado, las herramientas necesarias, lo que debe hacer, lo que no debe hacer y el contexto. Si el prompt que envía al sub-agente tiene menos de 30 líneas, lo considera insuficiente.
Y aquí viene lo más importante: no confía en lo que le dicen los sub-agentes. Después de cada delegación ejecuta lsp_diagnostics en todos los archivos modificados, lanza el build y los tests. Sin evidencia, la tarea no se considera completa.
Hephaestus: el trabajador autónomo profundo ¶

Si Sisyphus es el director, Hephaestus es ese ingeniero senior que le das una tarea y se la resuelve entera sin preguntar. Funciona con GPT-5.3 Codex y su prompt define un comportamiento concreto: “Opera como un Staff Engineer Senior. No adivinas. Verificas. No paras antes de tiempo. Completas.”
Hephaestus tiene una regla en su prompt que resulta reveladora: una lista de cosas que tiene prohibido decir. No puede preguntar “¿debería continuar con X?”, ni “¿quieres que ejecute los tests?”, ni detenerse tras una implementación parcial. La instrucción es tajante: “100% o nada.”
Su ciclo de trabajo sigue cinco fases:
- Explorar: lanza de 2 a 5 agentes de exploración en paralelo mientras lee archivos con herramientas directas.
- Planificar: lista los archivos a modificar, los cambios específicos y las dependencias.
- Decidir: si es trivial (menos de 10 líneas, un solo archivo) lo hace él. Si es complejo, delega.
- Ejecutar: cambios quirúrgicos o delegación con prompts exhaustivos.
- Verificar:
lsp_diagnosticsen todos los archivos modificados, build y tests.
Hephaestus también informa del progreso de forma proactiva: antes de explorar, después de descubrir algo, antes de ediciones grandes, cuando se bloquea. Eso convierte el trabajo del agente en algo que puedes seguir con claridad desde el terminal.
🧨 Última oprtunidad para recibir la dinamita que mereces sobre programación con IA el próximo domingo: Suscríbete gratis a Web Reactiva en https://webreactiva.com/newsletter
Oracle: el consultor de solo lectura ¶
Oracle funciona sobre GPT-5.3 Codex y es puro análisis. No escribe código. No lo modifica. Solo lee, razona y aconseja. Su prompt define un marco de decisión basado en lo que llama “minimalismo pragmático”: la solución correcta es la menos compleja que cumple los requisitos reales.
Las respuestas de Oracle siguen una estructura de tres niveles:
- Esencial (siempre): conclusión en 2-3 frases + plan de acción en 7 pasos máximo + estimación de esfuerzo (Quick, Short, Medium o Large).
- Expandido (cuando aplica): razonamiento y trade-offs clave + riesgos y mitigaciones.
- Casos límite (solo cuando es relevante): condiciones para escalar a una solución más compleja.
La regla de oro de Oracle: “Nunca sugieras añadir dependencias o infraestructura nueva a menos que te lo pidan.”
Librarian: el investigador ¶
Librarian trabaja con GLM-4.7 y es el experto en fuentes externas. Su prompt clasifica cada petición en cuatro tipos:
- Tipo A (conceptual): “¿Cómo uso esta librería?” → Descubrimiento de documentación + Context7 + búsqueda web.
- Tipo B (implementación): “¿Cómo está implementado X?” → Clona el repo, lee el código fuente, construye permalinks de GitHub.
- Tipo C (contexto): “¿Por qué se cambió esto?” → Issues, PRs, git blame, historial.
- Tipo D (exhaustivo): Investigación profunda combinando todas las herramientas.
Un detalle que muestra la atención al detalle del proyecto: el prompt de Librarian incluye una comprobación de fecha obligatoria. Antes de cualquier búsqueda, verifica el año actual para no buscar resultados del año anterior. Parece una tontería, pero evita un problema real con los modelos de IA que a veces se quedan “atrapados” en datos antiguos.
Explore: grep contextual del código ¶
Explore usa Claude Haiku 4.5 y es el agente más económico. Rápido, ligero y de solo lectura. Su misión es responder preguntas como “¿Dónde está implementado X?” o “¿Qué archivos contienen Y?”.
Su prompt exige tres cosas en cada respuesta: un análisis de intención (qué pide el usuario realmente, no solo lo que dice), ejecución en paralelo (mínimo 3 herramientas a la vez) y resultados estructurados con rutas absolutas y respuesta accionable. Si la respuesta obliga al usuario a preguntar “¿pero dónde?”, se considera un fallo.
Prometheus: el planificador estratégico ¶
Prometheus es el agente más complejo y el que mejor refleja la filosofía del proyecto. Su prompt empieza con una declaración en mayúsculas: “ERES UN PLANIFICADOR. NO ERES UN IMPLEMENTADOR. NO ESCRIBES CÓDIGO.”
Cuando le dices “implementa autenticación”, no lo interpreta como una orden de trabajo. Lo interpreta como “crea un plan de trabajo para implementar autenticación”. Esta reinterpretación es sistemática y no admite excepciones: incluso si el usuario dice “no planifiques, solo hazlo”, Prometheus se niega y explica por qué la planificación vale la pena.
Metis, Momus y Atlas ¶
Metis es la consultora previa al plan. Analiza cada petición y las clasifica en seis tipos de intención (refactorización, construcción desde cero, tarea media, colaborativa, arquitectura, investigación) con estrategias diferentes para cada una. Su trabajo es encontrar lo que a Prometheus se le escapa: intenciones ocultas, ambigüedades y patrones de “AI-slop” como la sobreingeniería o la inflación de alcance.
Momus, nombrado como el dios griego de la sátira que encontraba defectos hasta en las obras de los dioses, es el revisor implacable. Pero su prompt tiene un sesgo interesante hacia la aprobación: “Cuando tengas dudas, aprueba”. Solo rechaza planes por bloqueos reales (archivos referenciados que no existen, tareas imposibles de empezar, contradicciones internas) y nunca lista más de 3 problemas por revisión.
Atlas es el ejecutor de planes. Nunca escribe código. Solo delega, coordina y verifica. Su prompt exige que cada delegación incluya seis secciones obligatorias y un mínimo de 30 líneas. Después de cada delegación ejecuta verificación automatizada Y revisión manual del código línea por línea: “Si no puedes explicar lo que hace el código modificado, no lo has revisado.”
🔍 Un aspecto fascinante del proyecto es que cada agente tiene prompts optimizados para diferentes modelos. Los agentes que pueden funcionar con GPT tienen una versión del prompt adaptada a las características de GPT-5.3 Codex (instrucciones más compactas, restricciones explícitas de verbosidad, reglas de herramientas más directas). Los que funcionan con Claude tienen prompts que contrarrestan la tendencia de Claude a ser “excesivamente servicial”. Esta doble personalidad es lo que hace que el sistema funcione con proveedores distintos.

Construye agentes con criterio
Si te flipa cómo Sisyphus orquesta agentes, esta masterclass te enseña a construir el tuyo con criterio
Verás los seis niveles de arquitectura (tools, guardarraíles, memoria, skills, MCP, orquestación), evals con LLM as Judge y sistemas multiagénticos con código real en Open Code.
Entrar a la masterclass →6 niveles de arquitectura · En directo · Web Reactiva Premium · 15€/mes
Dos formas de trabajar ¶
Oh My OpenCode ofrece dos modos de trabajo que cubren escenarios muy diferentes. Y merece la pena entender en detalle cómo funciona cada uno por dentro.
Ultrawork: el modo “hazlo tú” ¶
Si tienes prisa o simplemente no quieres pensar demasiado en los detalles, incluye ultrawork o su abreviatura ulw en tu prompt:
ulw add authentication to my Next.js app
Eso es todo. Pero por debajo la maquinaria es bastante más elaborada de lo que parece. El flujo real que sigue Ultrawork tiene cinco pasos:
-
Clasificación: Sisyphus analiza tu petición y determina su tipo (trivial, explícita, exploratoria, abierta o ambigua). Una tarea trivial de un solo archivo la resuelve él mismo. Una tarea abierta como “add authentication” activa el ciclo completo.
-
Exploración en paralelo: Lanza múltiples agentes de fondo. Un
explorebusca patrones de autenticación existentes en tu código. Otroexplorebusca la estructura de archivos y convenciones de nombrado. Unlibrarianinvestiga las mejores prácticas de la librería que vayas a usar. Todo en paralelo, todo en segundo plano. -
Delegación inteligente: Con los resultados de la exploración, Sisyphus decide qué categoría y qué skills necesita cada sub-tarea. El componente de frontend va con
category="visual-engineering"y el skill defrontend-ui-ux. La lógica de backend va concategory="unspecified-high". Cada delegación incluye las seis secciones obligatorias. -
Ejecución con verificación: Cada sub-agente (Sisyphus-Junior) trabaja de forma autónoma. Cuando termina, Sisyphus ejecuta
lsp_diagnostics, lanza el build y comprueba los tests. Si algo falla, reutiliza la misma sesión del sub-agente (consession_id) para que no pierda el contexto de lo que ya hizo. -
Ciclo hasta completar: Repite los pasos 3 y 4 hasta que todo esté listo. Si un sub-agente falla tres veces seguidas, Sisyphus para, revierte al último estado funcional y consulta a Oracle antes de seguir.
Ultrawork funciona bien para la mayoría de tareas complejas donde confías en el criterio del sistema. Donde no funciona tan bien es cuando la tarea tiene ambigüedades de negocio que solo tú puedes resolver: ahí necesitas el flujo de Prometheus.
# Ejemplos de uso con Ultrawork
ulw fix the failing tests in the auth module
ulw refactor the payment service to use the new API
ulw create a dashboard component with charts
Prometheus: el modo preciso ¶
Para trabajo crítico o proyectos de varios días, el flujo Prometheus ofrece un control que ningún otro agente CLI proporciona. No es solo “planifica y ejecuta”. Es un proceso completo de consultoría, investigación, planificación, revisión y ejecución.
Paso 1: Activación. Pulsa Tab para cambiar al agente Prometheus o escribe @plan seguido de tu descripción. El agente entra en modo entrevista, que es su estado por defecto.
Paso 2: La entrevista. Prometheus no genera un plan a ciegas. Clasifica tu intención (refactorización, construcción nueva, tarea media, colaborativa, arquitectura o investigación) y adapta su estrategia de preguntas. Para una refactorización pregunta por comportamiento a preservar, cobertura de tests y estrategia de rollback. Para una construcción nueva lanza primero exploraciones para descubrir los patrones de tu codebase y te pregunta con evidencia.
Durante la entrevista, Prometheus mantiene un borrador en .sisyphus/drafts/ donde registra cada decisión, cada hallazgo de investigación y cada pregunta resuelta. Este borrador es su memoria externa: si la conversación es larga, no pierde contexto.
Después de cada turno de la entrevista, Prometheus ejecuta un checklist de auto-clearance:
- ¿Objetivo principal definido?
- ¿Límites de alcance establecidos (qué entra y qué no)?
- ¿Sin ambigüedades críticas?
- ¿Enfoque técnico decidido?
- ¿Estrategia de tests confirmada?
- ¿Sin preguntas bloqueantes pendientes?
Si todas las respuestas son “sí”, transiciona a la generación del plan de forma automática. No espera a que le digas “ya estoy listo”.
Paso 3: Consulta con Metis. Antes de generar el plan, Prometheus convoca a Metis para que busque lo que se ha pasado por alto: preguntas que debería haber hecho, guardarraíles necesarios, zonas de posible inflación de alcance, suposiciones sin validar.
Paso 4: Generación del plan. Con toda la información, genera un plan en .sisyphus/plans/{nombre}.md. El plan incluye un resumen ejecutivo (TL;DR), contexto completo, objetivos de trabajo con “Must Have” y “Must NOT Have”, estrategia de verificación, oleadas de ejecución en paralelo con matriz de dependencias y criterios de éxito.
Las tareas del plan se organizan en oleadas paralelas. Las tareas independientes van juntas: mientras una oleada escribe types y schemas, otra puede estar configurando el scaffolding del proyecto. El objetivo es tener entre 5 y 8 tareas por oleada. Menos de 3 indica que la división es insuficiente.
Paso 5: Revisión opcional con Momus. Prometheus te ofrece dos opciones: empezar a trabajar o pasar por la revisión de alta precisión con Momus. Si eliges revisión, Momus analiza el plan buscando bloqueos reales. Si rechaza, Prometheus corrige y reenvía. El bucle continúa hasta que Momus dice “OKAY”.
Paso 6: Ejecución con Atlas. Ejecutas /start-work y Atlas toma el control. Distribuye las tareas entre los sub-agentes, verifica cada resultado y gestiona los fallos reutilizando sesiones.
La magia está en que el trabajo sobrevive a las interrupciones. Si cierras la sesión, el estado se guarda en un archivo boulder.json. Al volver y escribir /start-work, retoma donde lo dejó:
Lunes 9:00
→ Prometheus entrevista y crea el plan
→ /start-work → Atlas empieza a ejecutar
→ Tareas 1-3 completadas
→ [Se cierra la sesión]
Lunes 14:00 (nueva sesión)
→ /start-work
→ "Retomando 'Build auth system' - 3 de 8 tareas completadas"
→ Atlas continúa desde la tarea 4
🔑 Regla de oro: Prometheus y Atlas van siempre juntos. Nunca uses Atlas sin un plan generado por Prometheus. Sin plan, el comportamiento es impredecible.
Categorías y skills: delegación inteligente ¶
Categorías ¶
Las categorías determinan qué modelo y configuración se usa para cada tipo de tarea:
- visual-engineering → Gemini 3 Pro. Para frontend, UI/UX, diseño, animaciones.
- ultrabrain → GPT-5.3 Codex. Para razonamiento lógico profundo y decisiones de arquitectura complejas.
- artistry → Gemini 3 Pro (modo max). Para tareas creativas.
- quick → Claude Haiku 4.5. Para cambios triviales, un solo archivo, correcciones de typos.
- unspecified-low → Claude Sonnet 4.5. Tareas genéricas de bajo esfuerzo.
- unspecified-high → Claude Opus 4.6 (modo max). Tareas genéricas de alto esfuerzo.
- writing → Gemini 3 Flash. Documentación y escritura técnica.
// Tarea de frontend
task(category="visual-engineering", load_skills=["frontend-ui-ux"], prompt="Create a responsive chart component")
// Tarea de arquitectura
task(category="ultrabrain", prompt="Design the payment processing flow")
// Tarea rápida
task(category="quick", prompt="Fix the typo in the login button")
Skills ¶
Los skills son inyecciones de conocimiento especializado que se añaden al prompt del sub-agente. frontend-ui-ux convierte al agente en un “diseñador-convertido-en-developer” que evita layouts genéricos de IA. playwright le da capacidades de automatización de navegador. git-master le enseña buenas prácticas de commits atómicos.
Puedes crear tus propios skills añadiendo archivos SKILL.md en .opencode/skills/ de tu proyecto o en ~/.claude/skills/ a nivel global. Si quieres aprender a diseñar skills efectivos para cualquier agente de terminal, tenemos una guía completa sobre skills para programadores que usan agentes de IA.
Categorías, skills, delegación inteligente entre modelos... la ingeniería agéntica avanza rápido y estamos viviendo la transformación en tiempo real. La newsletter de Web Reactiva te ayuda a entender el cambio: cada domingo, experiencias y recursos sobre IA en desarrollo para +6.700 developers.
Quiero esa dinamita 🧨Funcionalidades que marcan la diferencia ¶
Más allá de los agentes, Oh My OpenCode incluye un ecosistema de funcionalidades que lo convierten en algo más que un simple wrapper de modelos.
Más de 20 hooks de automatización ¶
Los hooks interceptan el flujo de trabajo en puntos clave. Estos son los más relevantes:
todo-continuation-enforcer es quizás el más útil. Uno de los problemas clásicos con los agentes de IA es que “se cansan” y dejan el trabajo a medias con un comentario tipo // rest of code here. Este hook detecta TODOs pendientes e inyecta un recordatorio que impide que el agente se dé por satisfecho. No puede cerrar la tarea si quedan tareas pendientes por completar.
context-window-monitor vigila el uso de la ventana de contexto y lanza alertas antes de que llegues al límite. Esto previene errores por desbordamiento que en otros agentes aparecen sin previo aviso.
session-recovery recupera la sesión de forma automática si algo falla: errores en bloques de pensamiento, interrupciones de red o caídas del proceso.
comment-checker valida los comentarios del código generado. keyword-detector detecta palabras clave en las conversaciones. rules-injector inyecta reglas personalizadas en el contexto del agente.
Integración con LSP ¶
Los agentes tienen acceso al Language Server Protocol, lo que les permite obtener diagnósticos en tiempo real, hacer renombramientos seguros con lsp_rename, buscar referencias con lsp_find_references y aplicar code actions. Puedes configurar servidores LSP personalizados, gestionar prioridades y mapear extensiones de archivo a servidores específicos.
En la práctica, esto reduce el “ir y venir” de correcciones. El agente detecta y corrige errores de imports, variables sin usar o problemas de tipos antes de enseñarte el código.
MCPs integrados ¶
Oh My OpenCode viene con dos servidores MCP activados por defecto (si quieres ver el ecosistema completo de plugins y MCPs de OpenCode, merece la pena explorarlo):
- Context7: obtiene documentación oficial actualizada de librerías. Cuando Librarian o cualquier sub-agente necesita consultar la API de una librería, Context7 le da la versión más reciente.
- grep.app: búsqueda ultrarrápida de código en millones de repositorios públicos de GitHub. Ideal para encontrar ejemplos de implementación reales.
Ambos se pueden desactivar desde la configuración si no los necesitas. Si todavía no tienes claro qué es MCP ni cómo configurarlo, consulta la guía para instalar y configurar servidores MCP donde lo explicamos paso a paso.
Funcionalidades experimentales ¶
El proyecto incluye varias funcionalidades en fase experimental:
- Preemptive Compaction: compacta el contexto de forma preventiva antes de alcanzar los límites de tokens.
- Aggressive Truncation: truncado más agresivo de la salida de herramientas para ahorrar contexto.
- Auto Resume: reanudación automática de sesiones tras una recuperación de errores.
- DCP (Dynamic Context Pruning): poda dinámica del contexto para una compactación más inteligente.
💡 La combinación de hooks, LSP y MCPs es lo que convierte a Oh My OpenCode en algo más que un orquestador de modelos. Es un entorno completo de desarrollo asistido por IA donde cada pieza tiene un propósito concreto. Los agentes en segundo plano, la acumulación de sabiduría entre tareas y la recuperación automática de sesiones hacen que trabajar con varios modelos a la vez deje de ser un dolor de cabeza para convertirse en un flujo natural.
Configuración y costes ¶
La configuración se gestiona con un archivo oh-my-opencode.json que puede estar a nivel de proyecto (.opencode/oh-my-opencode.json) o a nivel de usuario (~/.config/opencode/oh-my-opencode.json).
Un ejemplo real de configuración para alguien con Claude, OpenAI y Gemini:
{
"$schema": "https://raw.githubusercontent.com/code-yeongyu/oh-my-opencode/master/assets/oh-my-opencode.schema.json",
// Modelos específicos para cada agente
"agents": {
"oracle": { "model": "openai/GPT-5.3 Codex" },
"librarian": { "model": "zai-coding-plan/glm-4.7" },
"explore": { "model": "opencode/gpt-5-nano" }
},
// Modelos por categoría de tarea
"categories": {
"quick": { "model": "opencode/gpt-5-nano" },
"visual-engineering": { "model": "google/gemini-3-pro" }
}
}
Hablemos de dinero, porque aquí no hay atajos. Al orquestar varios modelos, estás consumiendo tokens de Anthropic, Google y OpenAI a la vez. El sistema intenta optimizar derivando tareas sencillas a modelos baratos como Haiku o Flash, pero las tareas complejas siguen pasando por Opus o GPT-5.3 Codex.
La recomendación del proyecto es usar suscripciones (Claude Pro/Max, ChatGPT Plus, Gemini) en lugar de APIs con pago por token. Si tienes acceso a las tres suscripciones, puedes exprimir bastante rendimiento sin que la factura se dispare.
Cada agente tiene una cadena de prioridad de proveedores. Si no tienes Gemini, el agente de frontend buscará entre tus otros proveedores disponibles. El sistema se adapta a lo que tengas.
Consejos prácticos para empezar ¶
Si decides probarlo, aquí van algunas recomendaciones basadas en lo que funciona bien:
-
Empieza con Ultrawork. No te compliques con Prometheus hasta que entiendas cómo se mueve el sistema. Un
ulw fix the failing testste dará una idea clara de lo que puede hacer. -
Invierte tiempo en la entrevista de Prometheus. Cuando uses el modo preciso, no tengas prisa. Cuanto mejor sea el plan, más rápida y limpia será la ejecución. Responde las preguntas con detalle.
-
Configura las categorías. Por defecto todas las categorías usan el modelo del sistema. Si no configuras categorías específicas, estarás usando Sonnet para tareas triviales donde Haiku bastaría. Revisa la sección de categorías de tu
oh-my-opencode.json. -
Aprovecha las tareas en segundo plano. Lanza investigaciones con Librarian o exploraciones con Explore mientras trabajas en otra cosa. Es productividad gratis.
-
No cambies la configuración por defecto sin motivo. El plugin funciona bien tal cual. Tocar los hooks o desactivar agentes sin entender qué hacen puede romper el flujo de orquestación.
-
Usa
bunx oh-my-opencode doctorcon frecuencia. Especialmente al principio, te ayuda a verificar que todo está en orden y que los modelos se resuelven como esperas.
¿Merece la pena? ¶
La delegación dinámica a agentes especializados es poderosa. Es como tener un mini equipo de desarrollo donde Opus maneja la planificación y el backend, Gemini se encarga del frontend y GPT-5.3 Codex hace las revisiones de arquitectura. Cada tarea va al modelo más adecuado, lo que en teoría da mejores resultados y un uso más eficiente de tokens.
La ejecución en segundo plano es un cambio real en la forma de trabajar, porque permite paralelismo de verdad. Y la integración con LSP junto con los hooks de continuación hacen que los agentes sean más fiables, con menos necesidad de supervisión.
Dicho esto, no es una herramienta para todo el mundo. La complejidad de configuración es mayor que instalar Cursor o usar Claude Code. Es una herramienta pensada para usuarios avanzados que no le tienen miedo a un archivo de configuración y que quieren exprimir al máximo lo que los modelos de IA pueden hacer desde el terminal.
Si trabajas con varios modelos, si el terminal es tu hábitat natural y si te atrae la idea de orquestar agentes como un equipo, Oh My OpenCode merece que le dediques una tarde de configuración.
El repositorio está en GitHub: code-yeongyu/oh-my-opencode. Y si después de probarlo te convence, los creadores te agradecerán una estrella.


Escrito con la ayuda de la IA generativa de Claude, fuentes fidedignas y con un human in the loop:
Dani Primo.
12 recursos para developers cada domingo en tu bandeja de entrada
Además de una skill práctica bien explicada, trucos para mejorar tu futuro profesional y una pizquita de humor útil para el resto de la semana. Gratis.