Tutorial: Cómo lanzar la IA con Docker Model Runner
La simplicidad de correr modelos de IA en local ¶
Docker Model Runner es una de esas herramientas que cambian silenciosamente la forma en que trabajamos. Si alguna vez has querido ejecutar modelos de IA localmente sin la complejidad habitual, esto es para ti. La promesa es simple: hacer que correr modelos de IA sea tan sencillo como ejecutar un contenedor.
El poder de la IA generativa ha estado creciendo exponencialmente, pero el proceso para implementar estos modelos sigue siendo innecesariamente complicado. Docker Model Runner elimina esta fricción, permitiéndote concentrarte en lo que realmente importa: construir aplicaciones, no configurar infraestructura.
Qué puedes hacer con Docker Model Runner ¶
Con esta herramienta, puedes:
- Descargar modelos directamente desde Docker Hub
- Ejecutar modelos de IA desde la línea de comandos
- Gestionar tus modelos locales (añadir, listar, eliminar)
- Interactuar con modelos mediante prompts o en modo chat
- Subir tus propios modelos a Docker Hub
Los modelos se descargan la primera vez que los usas y se almacenan localmente. Solo se cargan en memoria cuando los necesitas, optimizando así tus recursos. Y aunque la descarga inicial puede llevar tiempo (estos modelos pueden ser grandes), después quedan en caché para un acceso más rápido.
Antes de empezar ¶
Para usar Docker Model Runner necesitas:
- Docker Desktop 4.40 o superior
- Docker Desktop para Mac con Apple Silicon o Windows con GPUs NVIDIA
- Esta característica está actualmente en fase Beta
Habilitando Docker Model Runner ¶
El proceso para habilitar esta funcionalidad es directo:
- Ve a la pestaña Features in development en configuración
- En la pestaña Experimental features, selecciona Access experimental features
- Haz clic en Apply and restart
- Cierra y vuelve a abrir Docker Desktop para asegurar que los cambios surtan efecto
- Abre la vista de Settings en Docker Desktop
- Navega a Features in development
- Desde la pestaña Beta, marca la opción Enable Docker Model Runner
Ahora puedes usar el comando docker model en la terminal y ver e interactuar con tus modelos locales en la pestaña Models del Dashboard de Docker Desktop.
Los comandos esenciales ¶
Verificando el estado ¶
Para comprobar si Docker Model Runner está activo:
$ docker model status
Ver todos los comandos disponibles ¶
Para obtener ayuda y una lista de subcomandos:
$ docker model help
Descargar un modelo ¶
Para descargar un modelo desde Docker Hub:
$ docker model pull ai/smollm2
La salida será algo como:
Downloaded: 257.71 MB
Model ai/smollm2 pulled successfully
También puedes descargar modelos GGUF directamente desde Hugging Face:
$ docker model pull hf.co/bartowski/Llama-3.2-1B-Instruct-GGUF
Listar los modelos disponibles ¶
Para ver todos los modelos que tienes descargados:
$ docker model list
Ejecutar un modelo ¶
Hay dos formas principales de ejecutar un modelo:
Con un prompt único ¶
$ docker model run ai/smollm2 "Hola"
Salida:
¡Hola! ¿En qué puedo ayudarte hoy?
En modo chat interactivo ¶
$ docker model run ai/smollm2
Salida:
Interactive chat mode started. Type '/bye' to exit.
> Hola
¡Hola! Soy Qwen, un asistente de IA. ¿En qué puedo ayudarte hoy?
> /bye
Chat session ended.
También puedes usar el modo chat en el Dashboard de Docker Desktop seleccionando el modelo en la pestaña Models.
Ver los logs ¶
Para monitorear la actividad o depurar problemas:
$ docker model logs
Acepta las siguientes opciones:
-f/--follow: Ver logs con streaming en tiempo real--no-engines: Excluir logs del motor de inferencia
Eliminar un modelo ¶
Para eliminar un modelo descargado:
$ docker model rm <modelo>
Subir un modelo a Docker Hub
Para subir tu modelo a Docker Hub:
$ docker model push <namespace>/<modelo>
Etiquetar un modelo
Para especificar una versión o variante particular:
$ docker model tag
Si no proporcionas una etiqueta, Docker usa por defecto latest.
Usando la API compatible con OpenAI ¶
Una de las características más potentes de Docker Model Runner es su compatibilidad con la API de OpenAI, lo que facilita la integración con aplicaciones existentes.
Endpoints disponibles ¶
Una vez habilitada la característica, hay nuevos endpoints disponibles en:
- Desde contenedores:
http://model-runner.docker.internal/ - Desde procesos del host:
http://localhost:12434/(asumiendo que has habilitado el acceso TCP en el puerto 12434)
Los endpoints de gestión de modelos son:
POST /models/create
GET /models
GET /models/{namespace}/{name}
DELETE /models/{namespace}/{name}
Y los endpoints compatibles con OpenAI:
GET /engines/llama.cpp/v1/models
GET /engines/llama.cpp/v1/models/{namespace}/{name}
POST /engines/llama.cpp/v1/chat/completions
POST /engines/llama.cpp/v1/completions
POST /engines/llama.cpp/v1/embeddings
Ejemplos de uso de la API ¶
Desde un contenedor ¶
#!/bin/sh
curl http://model-runner.docker.internal/engines/llama.cpp/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "ai/smollm2",
"messages": [
{
"role": "system",
"content": "Eres un asistente útil."
},
{
"role": "user",
"content": "Por favor, escribe 500 palabras sobre la caída de Roma."
}
]
}'
Desde el host usando TCP ¶
#!/bin/sh
curl http://localhost:12434/engines/llama.cpp/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "ai/smollm2",
"messages": [
{
"role": "system",
"content": "Eres un asistente útil."
},
{
"role": "user",
"content": "Por favor, escribe 500 palabras sobre la caída de Roma."
}
]
}'
Usando el SDK de OpenAI ¶
También puedes utilizar el SDK oficial de OpenAI, modificando la URL base para que apunte a tu instancia local de Docker Model Runner:
import OpenAI from 'openai';
// Configura el cliente para usar Docker Model Runner local
const openai = new OpenAI({
baseURL: 'http://localhost:12434/engines/v1',
apiKey: 'sk-no-key-required' // No se necesita una clave real
});
async function generarJuegoSerpiente() {
const completion = await openai.chat.completions.create({
model: 'ai/smollm2',
messages: [
{
role: 'system',
content: 'Eres un desarrollador experto en JavaScript.'
},
{
role: 'user',
content: 'Genera el código completo para un juego de la serpiente en JavaScript usando canvas. El código debe ser funcional y bien comentado.'
}
]
});
console.log(completion.choices[0].message.content);
}
generarJuegoSerpiente();
Este ejemplo muestra cómo puedes aprovechar las herramientas habituales del ecosistema de OpenAI con tus modelos locales gestionados por Docker.
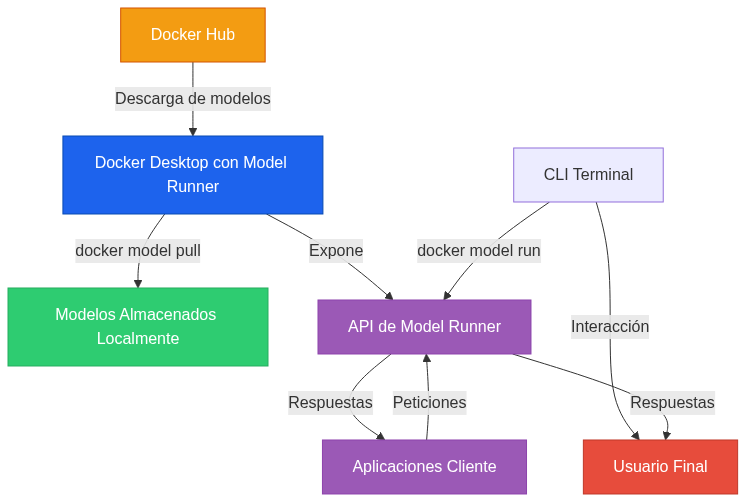
Integrando Docker Model Runner en tu ciclo de desarrollo ¶
Una vez que tienes Docker Model Runner configurado, puedes empezar a desarrollar aplicaciones de IA generativa. Si quieres probar una aplicación existente, aquí tienes los pasos:
-
Clona el repositorio de ejemplo:
$ git clone https://github.com/docker/hello-genai.git -
En tu terminal, navega al directorio
hello-genai -
Ejecuta
run.shpara descargar el modelo elegido y ejecutar la(s) aplicación(es) -
Abre tu aplicación en el navegador en las direcciones especificadas en el README del repositorio
Ahora puedes interactuar con tu propia aplicación de IA generativa, impulsada por un modelo local que se ejecuta completamente en tu máquina.
Modelos disponibles en Docker Hub ¶
Docker Model Runner te da acceso a una creciente colección de modelos de IA. A continuación, presentamos algunos de los modelos más destacados disponibles actualmente:
| Modelo | Descripción | Pulls promedio |
|---|---|---|
| ai/qwen3 | El modelo más reciente de la familia Qwen | 576 |
| ai/smollm2 | Modelo LLM pequeño optimizado para dispositivos edge y desarrollo local | 1,031 |
| ai/deepseek-r1-distill-llama | LLaMA destilado por DeepSeek, rápido y optimizado para tareas del mundo real | 1,026 |
| ai/llama3.3 | La versión más reciente de LLama 3 con razonamiento y generación mejorados | 316 |
| ai/llama3.2 | Actualización sólida de LLaMA 3, fiable para tareas de codificación, chat y Q&A | 627 |
| ai/mistral | Modelo abierto eficiente con rendimiento de primer nivel e inferencia rápida | 334 |
| ai/phi4 | Modelo compacto de Microsoft, sorprendentemente capaz en razonamiento y código | 187 |
| ai/qwen2.5 | Versión versátil de Qwen con mejores habilidades lingüísticas y mayor soporte | 221 |
| ai/gemma3 | La última versión de Gemma de Google, pequeña pero potente para chat y generación | 752 |
| ai/llama3.1 | LLama 3.1 de Meta: enfocado en chat, fuerte en benchmarks y preparado para multilingüe | 140 |
Esta es solo una muestra de los modelos disponibles. Puedes explorar la colección completa en Docker Hub para encontrar el modelo que mejor se adapte a tus necesidades específicas.
La verdadera ventaja: desarrollo local de IA sin complicaciones ¶
Lo que hace que Docker Model Runner sea tan valioso no es solo la tecnología subyacente, sino la simplicidad que aporta al proceso de desarrollo. En lugar de configurar entornos complejos o depender de APIs externas, puedes desarrollar, probar e iterar aplicaciones de IA generativa completamente en local.
Esto cambia fundamentalmente el ciclo de desarrollo, haciéndolo más rápido, más barato y con mayor control sobre tus datos. No es solo una herramienta más; es un nuevo paradigma para desarrollar aplicaciones de IA.
Aún estando en beta, Docker Model Runner ya muestra su potencial para hacer que la IA sea más accesible para todos los desarrolladores. La próxima vez que pienses en construir una aplicación que utilice modelos de lenguaje, considera si realmente necesitas depender de servicios externos cuando puedes tener la misma funcionalidad ejecutándose localmente con un simple comando.
La ventaja estratégica: Comparativa entre Docker Model Runner y Ollama ¶
En el panorama de las herramientas para ejecutar modelos de IA localmente, Ollama ha sido durante algún tiempo la opción preferida para muchos desarrolladores. Sin embargo, Docker Model Runner está posicionado para convertirse en el nuevo estándar de la industria por varias razones clave:
Integración nativa con Docker ¶
A diferencia de Ollama, que funciona como una herramienta independiente, Docker Model Runner se integra perfectamente en el ecosistema Docker que ya es familiar para millones de desarrolladores en todo el mundo. Esta integración significa que no necesitas aprender una nueva herramienta o sintaxis, simplemente usas los comandos Docker que ya conoces, añadiendo el subcomando model.
# Con Ollama necesitas aprender una nueva sintaxis
ollama run llama3
# Con Docker Model Runner usas el ecosistema Docker familiar
docker model run ai/llama3.2
Infraestructura de Docker Hub ¶
Docker Hub ofrece una infraestructura robusta, probada y escalable para alojar y distribuir modelos. Esto proporciona mayor confiabilidad y velocidad en comparación con la infraestructura menos madura de Ollama. Los modelos en Docker Hub también se benefician de las mismas características de seguridad, verificación y distribución que han sido perfeccionadas durante años para contenedores.
Interoperabilidad con el ecosistema Docker ¶
Docker Model Runner permite que los modelos de IA interactúen fácilmente con aplicaciones containerizadas, simplificando enormemente los flujos de trabajo de desarrollo e implementación. Puedes crear rápidamente arquitecturas completas donde los modelos de IA y otros servicios trabajan juntos sin problemas.
# Comunicación entre contenedores usando Docker Model Runner
docker run -it --rm my-application http://model-runner.docker.internal/
Rendimiento ¶
Docker Model Runner está diseñado desde cero para optimizar el rendimiento de los modelos más modernos. A diferencia de Ollama, que inicialmente priorizó la facilidad de uso sobre el rendimiento, Docker Model Runner aprovecha las optimizaciones y características avanzadas del ecosistema Docker para maximizar la velocidad y eficiencia.
Compatibilidad API ¶
Docker Model Runner ofrece compatibilidad completa con la API de OpenAI, permitiendo una migración sin problemas desde servicios en la nube hacia implementaciones locales sin cambiar una sola línea de código. Soporta todos los endpoints estándar con la misma estructura de peticiones y respuestas.
Aunque Ollama ha sido pionero en facilitar el acceso a modelos de IA locales, Docker Model Runner representa la evolución natural de esta tecnología. Al combinar la simplicidad con la potencia del ecosistema Docker, ofrece una solución más robusta, escalable y fácil de integrar que satisface tanto las necesidades de desarrolladores individuales como las de grandes organizaciones.
Si ya estás familiarizado con Docker, la transición a Docker Model Runner será prácticamente inmediata, mientras que obtener el mismo nivel de integración y capacidades con Ollama requeriría un esfuerzo significativamente mayor.
Cómo elegir el mejor modelo para usar con Docker ¶
Sección generada con LLM, puede contener imprecisiones.
Seleccionar el modelo adecuado para tu caso de uso puede marcar una gran diferencia en el rendimiento y la calidad de tus aplicaciones. Aquí te presentamos un árbol de decisión para ayudarte a encontrar el modelo que mejor se adapte a tus necesidades:
1. Evalúa tus recursos de hardware ¶
-
¿Tienes recursos limitados? (Menos de 8GB de RAM, sin GPU)
ai/smollm2- Modelo pequeño con 361.82M de parámetros, optimizado para dispositivos con recursos limitadosai/phi4- Modelo de 14B parámetros pero altamente optimizado para hardware modesto, requiere aproximadamente 9.1GB de almacenamiento
-
¿Tienes recursos moderados? (8-16GB de RAM, GPU básica)
ai/qwen3- Modelo de la familia Qwen que soporta 119 idiomas diferentes con excelente balance entre rendimiento y eficienciaai/gemma3- Modelo de Google de tamaño compacto pero potente para chat y generación
-
¿Tienes recursos abundantes? (16GB+ de RAM, GPU potente)
ai/llama3.3- La versión más reciente de LLama 3 con capacidades de razonamiento mejoradasai/deepseek-r1-distill-llama- LLaMA destilado optimizado para tareas complejas del mundo real
2. Define tu caso de uso principal ¶
-
¿Desarrollo y prototipado rápido?
ai/smollm2- Modelo LLM pequeño (361.82M parámetros) optimizado para ciclos rápidos de desarrolloai/qwen3- La última versión de Qwen que ofrece buen balance entre velocidad y capacidades
-
¿Generación de código?
ai/phi4- Modelo de Microsoft de 14B parámetros especializado en razonamiento y codificaciónai/llama3.2- Modelo multilingüe fiable en generación y comprensión de código, disponible en tamaños de 1B y 3B parámetros
-
¿Chatbots y asistentes virtuales?
ai/llama3.1- Modelo enfocado en conversaciones naturales con soporte multilingüeai/mistral- Modelo de 7B parámetros excelente para diálogos interactivos con rendimiento superior
-
¿Análisis y razonamiento?
ai/llama3.3- Versión avanzada de LLama con capacidades de razonamiento mejoradasai/deepseek-r1-distill-llama- Versión destilada del modelo DeepSeek optimizada para tareas analíticas complejas
3. Prioriza entre velocidad y precisión ¶
-
¿Necesitas respuestas inmediatas? (Prioridad: velocidad)
ai/smollm2oai/qwq- Modelos ligeros diseñados para inferencia rápida, ideales para aplicaciones en tiempo realai/llama3.2- La versión compacta (1B y 3B parámetros) ofrece buen rendimiento con inferencia rápida
-
¿Necesitas respuestas más precisas? (Prioridad: calidad)
ai/llama3.3- Modelo con mejoras significativas en razonamiento y generación respecto a versiones anterioresai/mistral- Modelo de código abierto con rendimiento de primer nivel y precisión competitiva
4. Consideraciones especiales ¶
-
¿Necesitas soporte multilingüe?
ai/qwen3- Soporta 119 idiomas y dialectos, lo que lo hace ideal para aplicaciones internacionalesai/llama3.1- Buena comprensión de múltiples idiomas como inglés, alemán, francés, italiano, español y más
-
¿Aplicación con restricciones de memoria?
ai/phi4- Modelo de Microsoft que ofrece sorprendente capacidad con una huella de memoria reducidaai/smollm2- Ocupa solo 256MB y funciona bien en dispositivos edge
-
¿Uso en producción?
ai/mistral-nemo- Versión de Mistral optimizada mediante NVIDIA NeMo para entornos empresarialesai/llama3.2- Incluye capacidades multilingües oficialmente soportadas para inglés, alemán, francés, italiano, portugués, hindi, español y tailandés
Recomendación para principiantes ¶
Si estás dando tus primeros pasos con Docker Model Runner, te recomendamos comenzar con ai/smollm2. Es rápido, requiere pocos recursos y ofrece una experiencia fluida que te permitirá familiarizarte con el flujo de trabajo sin frustraciones.
Una vez que te sientas cómodo, puedes explorar modelos más especializados según tus necesidades específicas.


Escrito con la ayuda de la IA generativa de Claude, fuentes fidedignas y con un human in the loop:
Dani Primo.
12 recursos para developers cada domingo en tu bandeja de entrada
Además de una skill práctica bien explicada, trucos para mejorar tu futuro profesional y una pizquita de humor útil para el resto de la semana. Gratis.