Comparativa Opus 4.6 vs GPT-5.3 Codex. ¿Cuál es el mejor para programadores?
(actualizado )
Nota. Este artículo está redactado con IA a partir de fuentes fidelignas. Todo, menos este párrafo.
🏄♂️ He probado los dos. Creo que las diferencias más significativas están más en las herramientas que rodean a estos modelos. Me siento más cómodo con Claude Code que con Codex, pero reconozco en este segundo producto un gran avance. Ambos son grandes consumidores de tokens, con lo que ambas empresas nos empujan a sus planes más caros para poder sacar provecho de las ventajas de grandes contextos y ejecuciones finas. Pruébalos, pero sobre todo, ponte con uno de ellos para que no te pille el toro.
Y ahora, la comparativa ;)
El 5 de febrero de 2026 no fue un miércoles cualquiera. Anthropic y OpenAI lanzaron sus modelos insignia casi a la misma hora, como dos boxeadores que saltan al ring al mismo tiempo sin esperar la campana.
Claude 4.6 Opus por un lado. GPT-5.3 Codex por el otro.
🔄 Actualización (junio 2026): esta comparativa es del lanzamiento de febrero de 2026. Ambos bandos han seguido moviendo ficha: Anthropic llegó a Opus 4.8 y OpenAI a GPT-5.5. Si lo que buscas es el cara a cara actualizado, esos dos análisis ya traen la comparativa hecha: Opus 4.8 frente a Opus 4.7, Sonnet 4.6 y GPT-5.5 y GPT-5.5 frente a Claude Opus 4.7. Lo que sigue mantiene su valor como retrato de aquel duelo Opus 4.6 vs Codex.
Y a los que estamos en medio, programando, entregando proyectos y tratando de no perder el norte con tanto avance, nos toca responder a una pregunta que no tiene nada que ver con benchmarks ni con hojas de cálculo: ¿qué tipo de programador quiero ser hoy?
Porque esa es la cuestión de fondo. No estamos ante una simple actualización de versión. Estamos ante dos filosofías radicalmente distintas de lo que significa trabajar con inteligencia artificial en el desarrollo de software.
Te cuento lo que he encontrado investigando a fondo ambos modelos, con datos, ejemplos reales de desarrolladores que los han puesto a prueba y, sobre todo, con la intención de que al terminar de leer esto sepas cuándo usar uno, cuándo el otro y cuándo los dos a la vez.
🧨 Última oprtunidad para recibir la dinamita que mereces sobre programación con IA el próximo domingo: Suscríbete gratis a Web Reactiva en https://webreactiva.com/newsletter
La era de la IA generalista ha terminado ¶
Durante años la historia se repetía: sale un modelo nuevo, es un poco más listo que el anterior, todos nos maravillamos y seguimos con nuestras vidas. GPT-4 era mejor que GPT-3.5. Claude 3 mejoraba a Claude 2. Y así hasta el infinito.
Eso se acabó.
Lo que ha pasado el 5 de febrero es una bifurcación. Anthropic y OpenAI han dejado de competir por el mismo trono para construir dos reinos distintos. Y eso cambia las reglas del juego para ti y para mí.
GPT-5.3 Codex es lo que muchos llaman el “demonio de la velocidad”. OpenAI ha apostado por la escala, la interacción a nivel de sistema operativo y la velocidad bruta. Codex es una máquina de producción masiva. Un modelo que parece terminar tu pensamiento antes de que pulses la última tecla.
Claude 4.6 Opus es el “arquitecto colaborador”. Anthropic ha priorizado el razonamiento profundo y la gestión de proyectos a gran escala. Opus no se limita a generar código. Cuestiona la arquitectura, anticipa riesgos que tú no habías visto y se comporta como un compañero senior con opiniones fundadas.
🧭 La elección entre uno y otro ya no es técnica. Es metodológica. Si necesitas mil líneas de boilerplate estándar, Codex te aplastará con su eficiencia. Si te enfrentas a una refactorización de un sistema heredado con deudas técnicas complejas, Opus es el compañero en el que querrás confiar.
Lo que hace especial a GPT-5.3 Codex ¶
OpenAI ha posicionado a Codex no como un modelo de lenguaje al uso, sino como un agente capaz de interactuar con el sistema operativo a un nivel que impresiona. Es un 25% más eficiente en inferencia que su predecesor, el 5.2. En la práctica, eso se traduce en que todo va rápido. Muy rápido.
Un desarrollador cronometró a Codex creando un componente completo de React con hooks, estilos y tests en aproximadamente 4,2 segundos. No es un error tipográfico. Cuatro segundos.
Pero la innovación real no está en la velocidad pura. Está en el “Mid-turn Steering”, la capacidad de intervenir mientras el modelo está ejecutando una tarea larga en la terminal. Antes, enviar un prompt era como lanzar una flecha: una vez disparada, solo podías esperar. Con Codex 5.3, la interacción es dinámica. Puedes corregir el rumbo sin invalidar el contexto de lo que ya estaba haciendo.
Piensa en pilotar un avión donde el piloto automático ajusta los flaps basándose en tus sugerencias en tiempo real. Eso es lo que se siente al trabajar con Codex en tareas largas.
Dónde brilla Codex ¶
- Generación masiva de código limpio. Patrones conocidos, tareas repetitivas, scripting. Codex es capaz de generar decenas de endpoints o funciones repetitivas en cuestión de segundos manteniendo código idiomático.
- Refactorizaciones mecánicas. ¿Tienes que convertir 50 componentes de clase a hooks en React? Codex lo hace antes de que cambies de ventana.
- Creación de tests. Genera casos de prueba a partir de un módulo dado sin pestañear.
- Prototipado rápido. Cuando necesitas que algo funcione ya, Codex es tu mejor aliado.
- Scripts de automatización. Todo lo que sea repetitivo y bien definido, Codex lo despacha con una eficiencia que asusta.
Un dato revelador: OpenAI afirma que Codex fue utilizado durante su propio entrenamiento para depurar errores críticos y gestionar despliegues internos. No solo genera código para otros. Se depura a sí mismo.
Las sombras de Codex ¶
No todo es perfecto. Codex optimiza el throughput por encima de la reflexión. Si la tarea es “que funcione ya”, es perfecto. Pero si requiere pensar en implicaciones arquitectónicas o en cómo afectará ese cambio dentro de seis meses, no profundiza tanto.
En pruebas iniciales, varios desarrolladores notaron que Codex escribía archivos usando comandos cat en lugar de editar de forma directa, consumiendo pasos y contexto de sobra. Un desarrollador lo comparó con “tratar de construir una casa describiendo por teléfono la posición de cada ladrillo”.
Y hay más. Un test exhaustivo de 48 horas en el que se pidió a ambos modelos construir aplicaciones completas reveló algo incómodo: Codex producía código que tenía buen aspecto pero que “se desmoronaba al tratar de usarlo”. Aplicaciones web con login roto por problemas de CSRF o tableros Kanban que ni siquiera pasaban de la pantalla de inicio.
Velocidad impresionante, pero con sombras. Cada semana salen novedades así en el mundo de la IA para developers. En la newsletter te llegan 12 recursos curados cada domingo con lo que de verdad importa: herramientas, plantillas y experiencias de +6.700 programadores.
Quiero esa dinamita 🧨Lo que hace especial a Claude 4.6 Opus ¶
Si Codex es velocidad, Opus es memoria y profundidad. Anthropic ha roto la barrera del contexto con una ventana de 1 millón de tokens. Pero la joya de la corona no es la cifra bruta. Es la Compaction API.
Cualquier programador que haya trabajado en sesiones largas con IA conoce el fenómeno de la “degradación cognitiva”: a medida que la conversación crece, el modelo empieza a olvidar detalles de la arquitectura definidos al principio. La Compaction API soluciona esto comprimiendo el historial de forma inteligente, reteniendo solo los nodos lógicos críticos.
Es como tener una memoria selectiva de genio: olvida el ruido, pero recuerda con exactitud por qué decidiste usar ese patrón de diseño hace tres días.
Además, Opus introduce el “Adaptive Thinking”. El modelo decide cuánto “pensar” antes de actuar. Ante consultas simples responde al instante. Pero cuando le planteas analizar la seguridad de un contrato inteligente o buscar condiciones de carrera en un sistema concurrente, entra en un estado de razonamiento profundo. Se nota una pausa deliberada. Y esa pausa vale oro. De hecho, Anthropic ha llevado esta línea mucho más lejos con Claude Mythos, un modelo capaz de explotar vulnerabilidades zero-day de forma autónoma.
Dónde brilla Opus ¶
- Diseño de sistemas. Puede discutir trade-offs como el teorema CAP, requisitos de consistencia y proponer diferentes enfoques con pros y contras honestos.
- Depuración compleja. Si algo “solo falla en producción bajo carga”, Opus colabora pensando paso a paso qué podría estar sucediendo en lugar de lanzar un parche rápido.
- Revisión de código en zonas críticas. Un desarrollador le pasó un Pull Request con condiciones de carrera sutiles y Opus las encontró. GPT-5.3, por su parte, contestó “todo se ve bien” sin notar los fallos.
- Decisiones de arquitectura. No solo implementa. Ofrece opiniones fundadas sobre por qué elegir un método u otro.
- Proyectos de largo recorrido. La ventana de contexto de un millón de tokens le permite analizar decenas de archivos juntos y realizar cambios informados en función de todo el código relevante.
Un usuario compartió que Opus le respondió algo así: “Esta solución funcionará, pero ¿has considerado esta otra arquitectura por estas razones que no habías pensado?”. Ese tipo de insight es el que marca la diferencia entre un asistente y un colaborador real.
Las sombras de Opus ¶
Es más lento. Notablemente más lento. Y los desarrolladores sospechan que es intencionado, porque está pensando más. Hay reportes de usuarios que vieron a Opus trabajando en segundo plano durante minutos en tareas complicadas, consumiendo su contexto mientras planifica.
También tiene mayor varianza en sus respuestas. Es muy creativo, pero a veces informa éxito cuando en realidad falló, o hace cambios no solicitados que requieren supervisión cuidadosa.
Y el precio. Con el plan Max de 100 dólares al mes frente a los 20 del plan Plus de ChatGPT que incluye Codex, la diferencia económica es notable. Es “un MacBook Air de diferencia al año”, como apuntó un comentarista en Reddit.
💰 Un equipo que hizo benchmarks sobre su propio código Ruby on Rails encontró que Codex resolvía tareas por aproximadamente 1 dólar en cómputo frente a los 5 dólares que costaba Opus en promedio. Pero en otro test de 48 horas construyendo aplicaciones completas, Opus entregó 5 de 7 apps funcionales mientras Codex no ganó en ninguna.
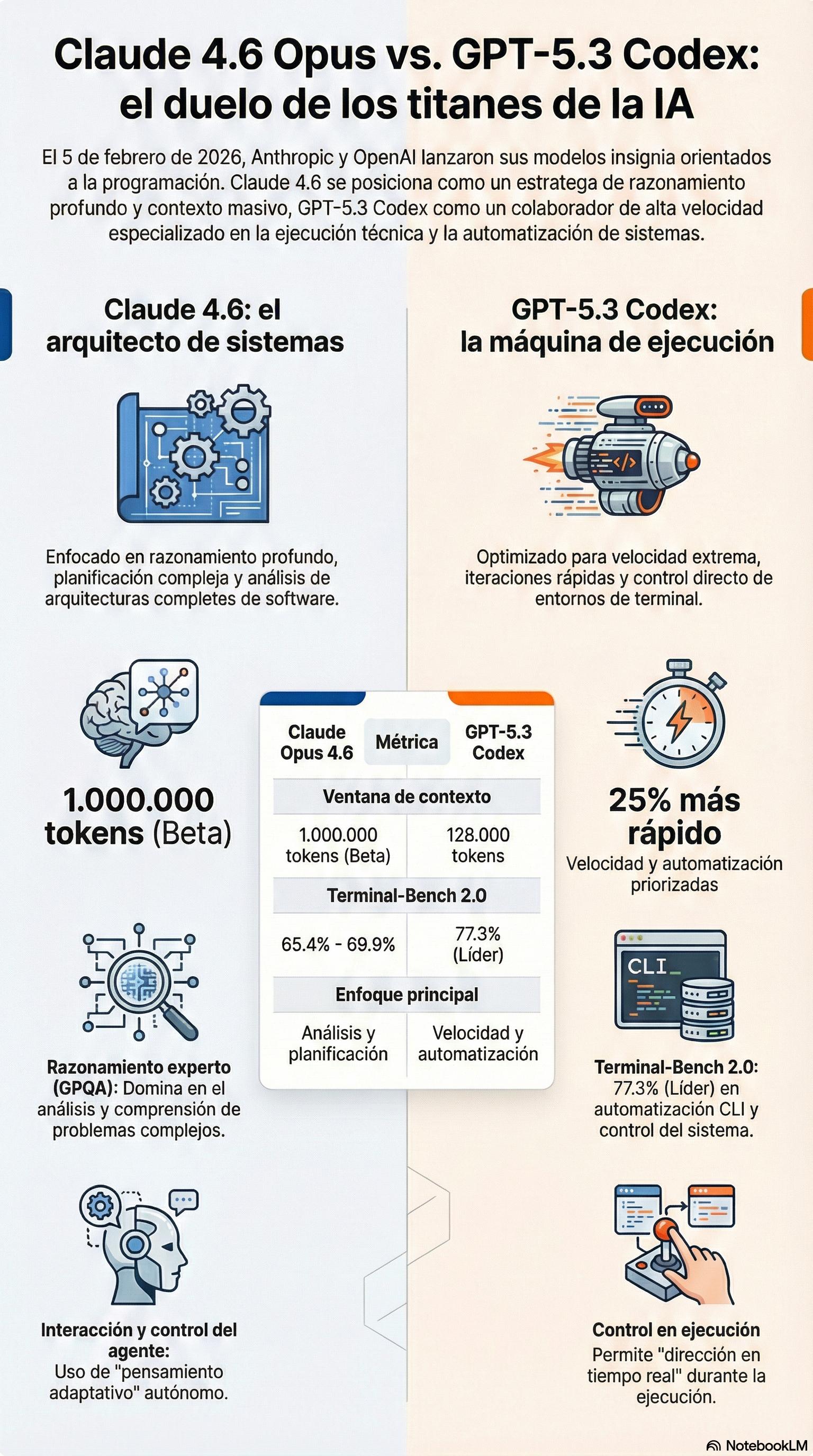
Los benchmarks: números que cuentan historias (con matices) ¶
Vamos a los datos duros, pero con un aviso previo. Los benchmarks son como las estadísticas en el fútbol: te dicen muchas cosas, pero no te cuentan el partido completo.
Dónde gana Codex:
- Terminal-Bench 2.0 (tareas de línea de comandos): Codex marca un 77,3% frente al 65,4% de Opus. En entornos de ejecución real en terminal, Codex es superior.
- Velocidad de inferencia: 25% más rápido que GPT-5.2. Esto no es un benchmark, es una ventaja tangible en cada interacción.
- Coste por tarea: En pruebas sobre código Ruby on Rails real, Codex generó código con puntuación de calidad de 0,70 frente al 0,61 de Opus, a un coste 7 veces menor.
Dónde gana Opus:
- SWE-Bench Verified (resolución de bugs reales): Opus alcanza un 79,4% y con el prompting adecuado puede llegar al 81,42%.
- GPQA Diamond (programación tipo olímpica): 77,3% de Opus frente al 73,8% de Codex.
- MMLU Pro (conocimiento académico/profesional): 85,1% frente a 82,9%.
- Humanity’s Last Exam (razonamiento multidisciplinar): primer puesto para Opus. Codex ni siquiera tiene datos publicados aquí.
El “Swiftagon”: cuando los benchmarks se vuelven reales ¶
Un enfrentamiento directo sobre una base de código de 4.200 líneas de Swift para visión artificial puso las cosas en perspectiva. Claude tardó 10 minutos en su análisis frente a los 4 minutos de Codex. Pero Claude identificó un error de “double-release” en la gestión de memoria que Codex pasó por alto.
Lo más interesante: Claude detectó el problema, lo clasificó como “Alta Severidad”, razonó sobre él en el mismo output y terminó degradándolo a “Media”, explicando que aunque el código era correcto por un invariante oculto, era un “olor técnico” peligroso para futuras refactorizaciones.
Ese nivel de análisis no aparece en ningún benchmark.
El proyecto Python TUI de 3 años ¶
Otra prueba: una aplicación de gestión de proyectos de miles de líneas con una interfaz TUI compleja. El requerimiento incluía una nueva navegación “spring-loaded” con atajos de teclado específicos. Codex completó la tarea en 11 minutos, interpretando intenciones que no estaban especificadas al 100%. Opus pasó 14 minutos solo planificando y al ejecutar el plan produjo un error que requirió una segunda iteración.
Aquí Codex demostró que su capacidad de “captar la vibra” de la intención del programador es, a día de hoy, superior en ciertos escenarios.
🎯 Un desarrollador resumió el patrón así: “Codex lidera en tareas muy definidas y acotadas. Opus tiende a brillar en tareas de múltiples pasos con incertidumbre donde puede desplegar su planificación”.
Diseño de interfaces: cuando la estética importa ¶
Hay un aspecto que no suele aparecer en las comparativas técnicas pero que marca diferencias reales: la calidad visual del código generado para interfaces.
Al poner a ambos modelos a construir un clon de Twitter y un juego de Blackjack, la diferencia no fue solo funcional. Codex entregó un esqueleto que cumplía los requisitos pero se sentía como un manual de instrucciones: gris, utilitario, funcional sin alma. Claude, en cambio, asumió el rol de Product Designer. Para el Blackjack, diseñó una interfaz con un tapete verde de casino usando Tailwind CSS. Para el clon de Twitter, estructuró componentes de Next.js listos para producción con una jerarquía visual cuidada y comportamientos móviles impecables.
Si eres desarrollador frontend o emprendedor que construye solo, esta capacidad de Opus para entender la “ergonomía visual” puede ahorrarte horas de trabajo con un diseñador. No solo quieres código que funcione. Quieres código que a tus usuarios les resulte agradable de usar.
La frontera de la ciberseguridad ¶
Algo que no puede pasar desapercibido: OpenAI ha clasificado a GPT-5.3 Codex como modelo de “Alto Riesgo” en ciberseguridad bajo su Marco de Preparación. Es la primera vez que lo hacen.
Codex es capaz de detectar y parchear vulnerabilidades de forma autónoma. En benchmarks de CTF (Capture The Flag), alcanza un 77,6% de efectividad. Claude se sitúa cerca, con un 78% aproximado en pruebas similares. Ambos modelos son herramientas poderosas para la defensa.
Pero eso mismo los convierte en armas de doble filo. La potencia que te permite encontrar una brecha en tu código es la misma que podría explotarla en manos equivocadas. OpenAI ha respondido con una “capa de seguridad estratificada” y un programa de Trusted Access for Cyber con incentivos para integrar Codex en flujos de defensa legítimos.
Para los que trabajamos en desarrollo web, la lección práctica es clara: estos modelos pueden convertirse en tus mejores auditores de seguridad si los integras bien en tu pipeline de revisión de código.
Benchmarks, ciberseguridad, flujos de trabajo... la transformación IA del software se mueve rápido. Desde 2018 ayudamos a entender el cambio con una newsletter gratuita cada domingo. Los suscriptores también aportan sus experiencias y aprendizajes.
Apúntate gratis →El flujo de trabajo híbrido: el verdadero ganador ¶
La conclusión más inteligente de todo este análisis no es elegir bando. Los desarrolladores que están sacando más partido son los que usan ambos modelos juntos mediante el Model Context Protocol (MCP).
La estrategia es conectar Codex como un servidor MCP dentro del entorno de Claude Code. Esto permite escenarios que parecen sacados de ciencia ficción:
El duelo de planificación. Pides a Opus que diseñe el plan de arquitectura para una funcionalidad nueva. Luego usas un comando para que Codex revise el plan. Si hay discrepancias, les pides que “discutan” entre sí hasta llegar a un consenso.
Ejecución en paralelo. Claude se encarga de la lógica de negocio y el diseño de componentes, mientras Codex genera tests masivos y boilerplate de API a una velocidad que Claude no puede igualar.
Aquí tienes un ejemplo de cómo configurar Codex como servidor MCP en tu archivo ~/.claude.json:
{
"mcpServers": {
"codex": {
"type": "stdio",
"command": "codex",
"args": [
"mcp-server",
"-c",
"model=gpt-5.3-codex",
"-c",
"reasoning_effort=high"
]
}
}
}
Con esta configuración, Claude puede “delegar” tareas de ejecución rápida a Codex. El desarrollador se convierte en el director de una orquesta de inteligencias especializadas.
Un ingeniero compartió su flujo habitual: usa GPT-5.3 para migraciones, refactorizaciones de patrón claro, generación de tests y prototipado. Y Opus para diseño de sistemas, debugging complejo, code review en rutas críticas y resolver problemas enrevesados. En la práctica, Codex le generó 30 handlers de API siguiendo un patrón en unos 10 minutos, y luego pasó esa salida a Opus para revisar el middleware de autenticación y la estrategia de caché. Opus se tomó 30 minutos analizando y detectó un par de fallos que el desarrollador no había visto.
Velocidad más confianza. Eso es lo que consigues cuando dejas de pensar en “cuál es mejor” y empiezas a pensar en “cuándo uso cada uno”.
Agent Teams: la carta oculta de Opus ¶
Una funcionalidad que merece atención especial es Agent Teams dentro de Claude Code. Permite que Opus lance múltiples sub-agentes de IA que colaboran en un mismo proyecto, como un equipo de programadores: un agente para el frontend, otro para el backend, otro para la base de datos.
Un desarrollador compartió un caso que suena casi irreal: Opus, usando Agent Teams, refactorizó por completo un archivo monolítico enorme. Al mismo tiempo escribió tests, implementó un feature flag para alternar entre la versión vieja y la nueva, comparó las diferencias en ejecución, verificó que no hubiera regresiones, hizo commit de los cambios, pusheó al repositorio y cerró más de 50 tickets de issues.
Todo mientras el desarrollador estaba en una reunión.
En menos de una hora.
Si quieres profundizar en cómo funcionan Agent Teams y cuándo merece la pena usar Opus frente a Sonnet, tenemos una comparativa dedicada entre Sonnet 4.6 y Opus 4.6.
Tabla comparativa rápida ¶
| Criterio | GPT-5.3 Codex | Claude 4.6 Opus |
|---|---|---|
| Enfoque | Velocista interactivo | Pensador autónomo |
| Velocidad | Muy alta (+25% vs GPT-5.2) | Más lento, reflexivo |
| Contexto | ~400.000 tokens | Hasta 1.000.000 tokens (beta) |
| Fortaleza principal | Producción masiva de código limpio | Análisis profundo y diseño de sistemas |
| Debilidad principal | No anticipa implicaciones a largo plazo | Mayor varianza, puede hacer cambios no solicitados |
| Precio | ~20 $/mes (ChatGPT Plus) | ~100 $/mes (plan Max) |
| Ideal para | Boilerplate, migraciones, tests, prototipos | Arquitectura, debugging, code review, problemas complejos |
El código sigue siendo cosa tuya ¶
Con toda esta tecnología, con dos modelos que hacen cosas que hace dos años parecían imposibles, hay algo que no cambia: la responsabilidad es tuya.
Codex puede generar 30 endpoints en 10 minutos. Opus puede encontrar una condición de carrera que nadie más vio. Pero ninguno de los dos sabe qué necesita tu negocio, qué esperan tus usuarios ni qué trade-offs son aceptables en tu contexto específico.
La IA puede escribir el código, sugerir la arquitectura y detectar sus propios errores. Pero solo tú puedes decidir si el resultado final tiene sentido y propósito.
🧩 El futuro de programar ya no consiste en escribir líneas de código. Consiste en gestionar un equipo de agentes inteligentes. La era del “modelo para todo” ha terminado. Lo que viene es un ecosistema donde la velocidad de Codex y la profundidad de Opus son dos caras de la misma moneda. Y tú eres quien decide cuándo lanzar cada una.
No te cases con una herramienta. Aprende a dirigir la orquesta.
Si quieres ampliar esta comparativa con Gemini 3.1 Pro, GLM-5 y otros modelos open source, consulta nuestra guía de los mejores modelos de IA para programar en 2026. También puedes ver cómo Gemini 3.1 Pro compite a mitad de precio con Opus 4.6. Y si ya has visto el lanzamiento de GPT-5.4, tenemos la comparativa entre GPT-5.4 y Opus 4.6 con benchmarks actualizados y flujo de trabajo híbrido.
Fuentes ¶
- The Real Winner of the Opus 4.6 vs GPT-5.3 Launch Week (It’s Not What You Think) - r/vibecoding
- GPT-5.3-Codex | Hacker News
- GPT 5.3 Codex vs. Opus 4.6: The Great Convergence - Every.to
- GPT 5.3 Codex vs Claude Opus 4.6: An overview of the new AI frontier - eesel.ai
- Claude Opus 4.6 vs GPT-5.3 Codex: Complete Comparison - Digital Applied
- GPT-5.3 Codex vs Opus 4.6: We benchmarked both on our production Rails codebase — the results are brutal - r/ClaudeAI
- I Spent 48 Hours Testing Claude Opus 4.6 & GPT-5.3 Codex - Medium
- Claude Opus 4.6 vs OpenAI Codex 5.3: Which is Better? - Analytics Vidhya
- Codex changelog - OpenAI for developers
- GPT-5.3-Codex System Card - OpenAI


Escrito con la ayuda de la IA generativa de Claude, fuentes fidedignas y con un human in the loop:
Dani Primo.
12 recursos para developers cada domingo en tu bandeja de entrada
Además de una skill práctica bien explicada, trucos para mejorar tu futuro profesional y una pizquita de humor útil para el resto de la semana. Gratis.