Buenas prácticas para crear skills de agentes de IA
Si estás creando skills para agentes de IA y no funcionan como esperabas, probablemente estés cayendo en errores que tienen solución.
Un skill no es un tutorial. Un skill no es documentación. Un skill es un mecanismo para transferir conocimiento experto a un modelo de IA. Y esa diferencia lo cambia todo.
En este artículo vas a encontrar los errores más comunes al diseñar skills y cómo evitarlos. Cada punto viene con su ejemplo malo y su versión corregida, con las razones detrás de cada decisión.
Si todavía no tienes claro qué son los skills o cómo funcionan dentro de los agentes de IA, te recomiendo que empieces por Skills para programadores: saca todo el provecho de los agentes de IA. Y si lo que necesitas es decidir qué tipo de skill crear, Anthropic ha publicado una taxonomía de 9 categorías para organizar sus cientos de skills que funciona como mapa. Ahí tienes la base para entender lo que viene ahora.
Preparado el terreno, vamos con las buenas prácticas.
1. El campo description es más importante de lo que crees ¶
Aquí es donde la mayoría de skills fracasan antes de empezar. Y no exagero.
El agente de IA tiene acceso a decenas o cientos de skills. Cuando recibe una petición del usuario, necesita decidir cuál activar. ¿Cómo lo hace? Leyendo las descripciones. Solo las descripciones. El cuerpo del skill no se carga hasta que la decisión ya está tomada.
Esto significa que puedes tener el mejor skill del mundo, con instrucciones perfectas y ejemplos brillantes. Si la descripción es vaga, el agente nunca lo activará.
🔑 La descripción es la puerta de entrada. Si está cerrada con llave y sin cartel, nadie va a llamar.
❌ Descripción que no funciona ¶
---
name: document-helper
description: Ayuda con tareas de documentos
---
¿Qué documentos? ¿Qué tareas? ¿Cuándo debería el agente usar esto? El modelo no tiene forma de saberlo.
🧨 Última oprtunidad para recibir la dinamita que mereces sobre programación con IA el próximo domingo: Suscríbete gratis a Web Reactiva en https://webreactiva.com/newsletter
✅ Descripción que sí funciona ¶
---
name: docx-processing
description: Crea, edita y analiza archivos .docx con soporte para cambios registrados, comentarios y formato profesional. Usa este skill cuando trabajes con documentos de Word, necesites insertar tablas, aplicar estilos corporativos o exportar a PDF desde un .docx.
---
La diferencia está en tres elementos que toda descripción necesita:
Cada semana, experiencias y aprendizaje sobre desarrollo web e IA en tu bandeja de entrada.
Únete a más de 6.700 developers que ya reciben la newsletter.
Suscríbete gratis →- QUÉ hace: crear, editar, analizar archivos .docx
- CUÁNDO usarlo: cuando trabajes con documentos de Word, tablas, estilos
- PALABRAS CLAVE: .docx, Word, PDF, tablas, estilos corporativos
El agente necesita keywords para hacer match con la petición del usuario. Si el usuario dice “hazme un informe en Word”, el agente busca skills que mencionen “Word” o “.docx” en su descripción. Sin esas palabras clave, tu skill es invisible.
Más ejemplos de descripciones problemáticas ¶
# ❌ Demasiado genérica
description: Un skill útil para varias tareas
# ❌ Solo dice qué, no cuándo
description: Procesa archivos PDF
# ❌ Usa jerga interna que el modelo no entiende
description: Gestiona el workflow de Q3 reports
Y sus versiones corregidas:
# ✅ Específica y con triggers
description: Extrae texto y tablas de archivos PDF, rellena formularios y combina múltiples documentos. Usa cuando el usuario mencione PDFs, extracción de datos o fusión de documentos.
# ✅ Incluye escenarios concretos
description: Genera presentaciones en formato .pptx con diseño profesional. Activa este skill cuando el usuario pida crear slides, presentaciones, pitch decks o material para reuniones.
2. No le cuentes al modelo lo que ya sabe ¶
Este es el error más común y el más costoso. Literalmente costoso, porque cada token que usas explicando cosas básicas es un token que no puedes usar para conocimiento experto.
Claude ya sabe qué es un PDF. Ya sabe cómo funciona Python. Ya conoce los patrones de programación estándar. Cuando tu skill dedica párrafos a explicar estos conceptos, estás comprimiendo conocimiento que el modelo ya tiene.
La fórmula es simple:
Buen Skill = Conocimiento experto − Lo que Claude ya sabe
❌ Skill que explica lo obvio ¶
## Qué es un archivo PDF
PDF significa Portable Document Format. Es un formato de archivo desarrollado
por Adobe que preserva el formato del documento independientemente del software,
hardware o sistema operativo utilizado para visualizarlo.
## Cómo abrir un archivo en Python
Para abrir un archivo en Python, usamos la función open():
file = open('documento.pdf', 'rb')
content = file.read()
file.close()
Todo esto Claude lo sabe. Cada línea es espacio desperdiciado.
✅ Skill que aporta conocimiento experto ¶
## Decisiones críticas en extracción de PDF
| Situación | Herramienta primaria | Fallback | Cuándo usar fallback |
| ------------- | -------------------- | ------------- | ------------------------------------ |
| Texto simple | pdftotext | PyMuPDF | Cuando necesites info de layout |
| Tablas | camelot-py | tabula-py | Cuando camelot falle con bordes |
| PDF escaneado | - | Tesseract OCR | Siempre que pdftotext devuelva vacío |
### Problemas comunes y soluciones
- **PDF escaneado detectado como texto**: Si pdftotext devuelve cadena vacía pero
el PDF tiene contenido visible, aplica OCR primero.
- **Tablas fragmentadas**: camelot funciona mejor con tablas de bordes definidos.
Para tablas sin bordes visibles, usa tabula con stream=True.
La diferencia es brutal. El segundo ejemplo transfiere conocimiento que solo alguien con experiencia en procesamiento de PDFs tendría. Son decisiones, trade-offs, casos límite. Cosas que no están en la documentación básica de ninguna librería.
💡 Antes de escribir cada sección de tu skill, pregúntate: “¿Claude ya sabe esto?” Si la respuesta es sí, bórralo.
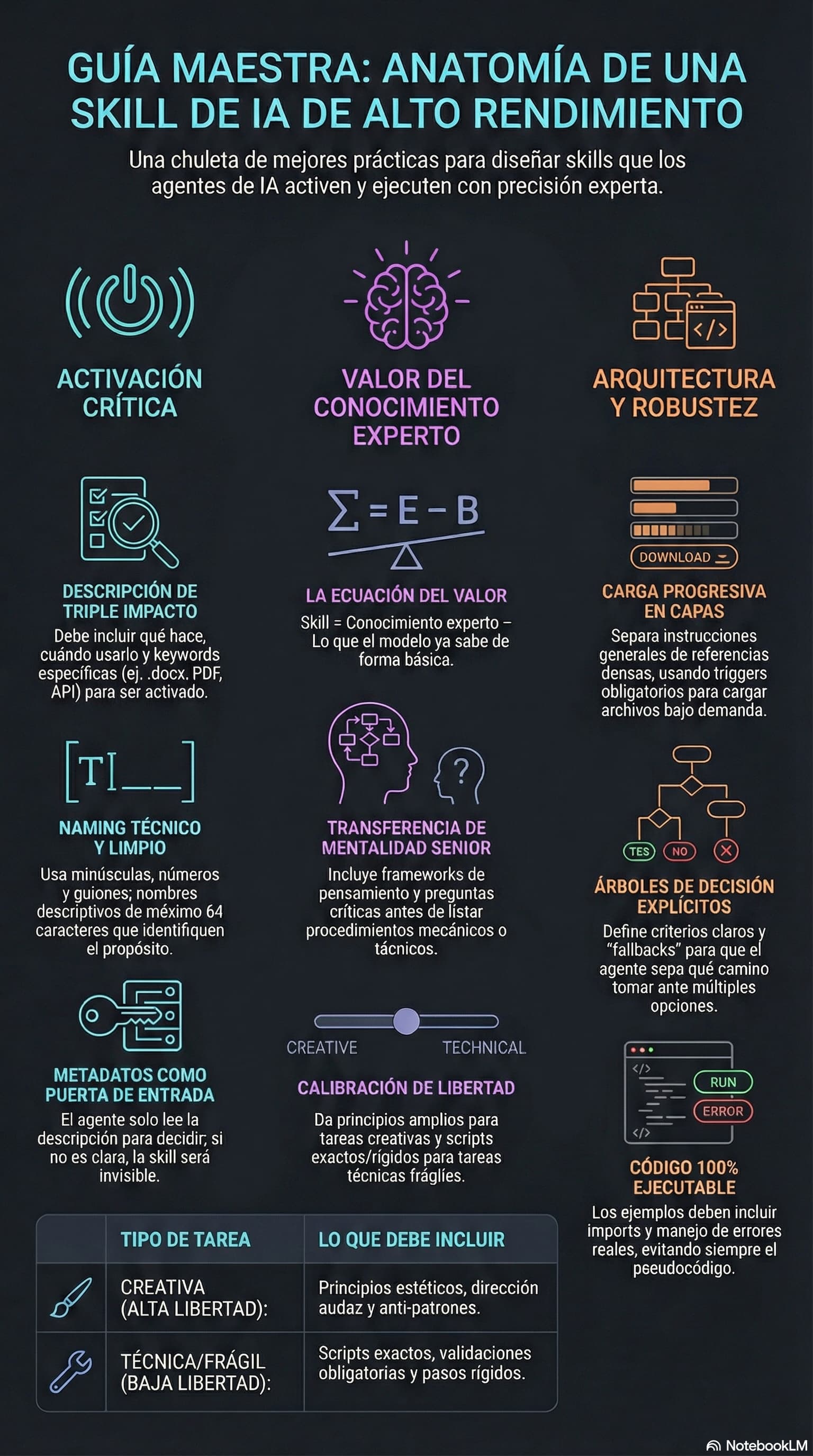
3. Transfiere mentalidad, no solo procedimientos ¶
La diferencia entre un junior y un senior no está en saber “cómo hacer las cosas”. Está en saber “cómo pensar sobre los problemas”.
Un skill que solo lista pasos mecánicos pierde la oportunidad de transferir esa forma de pensar. Y eso es lo que realmente hace valioso a un experto.
❌ Procedimiento mecánico ¶
## Pasos para crear un documento
1. Abre el archivo de plantilla
2. Modifica el título
3. Añade el contenido
4. Guarda el archivo
5. Verifica que se guardó correctamente
Esto no aporta nada. Claude sabe abrir archivos y guardarlos.
✅ Framework de pensamiento + procedimiento específico ¶
## Antes de crear cualquier documento, pregúntate:
- **Propósito**: ¿Qué problema resuelve este documento? ¿Quién lo va a leer?
- **Restricciones**: ¿Hay requisitos de formato corporativo? ¿Límite de páginas?
- **Diferenciación**: ¿Qué hace memorable este documento frente a otros similares?
## Workflow específico para OOXML (esto Claude no lo sabe)
1. Descomprime el .docx (es un ZIP): `unzip documento.docx -d temp/`
2. Localiza el contenido en `temp/word/document.xml`
3. Edita el XML respetando namespaces (critical: no borres xmlns)
4. Valida la estructura ANTES de reempaquetar
5. Reempaqueta: `zip -r documento_editado.docx temp/*`
6. Verifica abriendo en Word (el validador interno es más estricto)
El framework de pensamiento cambia cómo el modelo aborda el problema. El procedimiento específico de OOXML es conocimiento que Claude probablemente no tiene, porque no está en tutoriales básicos.
Hay que distinguir entre tres tipos de procedimientos:
- Genéricos: abrir, leer, escribir, guardar. Claude los sabe. Bórralos.
- Específicos de dominio: workflow OOXML, secuencias de validación, orden crítico de operaciones. Estos sí aportan.
- Frameworks de pensamiento: preguntas que hacerse antes de actuar. Cambian el enfoque del modelo.
4. La lista de “NUNCA hagas esto” vale oro ¶
La mitad del conocimiento experto es saber qué NO hacer. Un diseñador senior ve un gradiente morado sobre fondo blanco y le rechinan los dientes. Sabe que eso grita “generado por IA”. Esa intuición viene de haber cometido errores y haberlos visto en otros.
Claude no ha cometido esos errores. No sabe que Inter es una fuente sobreutilizada. No sabe que ciertos patrones de diseño son clichés. Necesita que se lo digamos de forma explícita.
❌ Advertencias vagas ¶
## Consideraciones
- Evita cometer errores
- Ten cuidado con los casos límite
- Considera las mejores prácticas
Esto no dice nada. Es ruido.
✅ Anti-patrones específicos con razones ¶
## NUNCA hagas esto
- **NUNCA uses fuentes genéricas de IA** (Inter, Roboto, Arial) → Delatan origen
automatizado. Usa fuentes con personalidad: IBM Plex, Source Serif, JetBrains Mono.
- **NUNCA apliques border-radius por defecto a todo** → Es el sello de UI perezosa.
Decide conscientemente: bordes duros para seriedad, redondeados suaves para
amabilidad, muy redondeados solo para elementos pill/tag.
- **NUNCA combines más de 2 familias tipográficas** → Crea caos visual. Una para
títulos, otra para cuerpo. Máximo.
- **NUNCA uses gradientes morados sobre blanco** → Es el cliché visual de "esto
lo hizo una IA". Si necesitas gradientes, usa tonos de un mismo color o
combinaciones menos predecibles.
Cada anti-patrón tiene su razón. No es “no lo hagas porque sí”, es “no lo hagas porque X consecuencia negativa”. Eso permite al modelo generalizar y aplicar el principio en situaciones nuevas. Un ejemplo excelente de este enfoque son las skills de Impeccable, que empaquetan anti-patrones de diseño en 17 comandos para que tu agente deje de generar interfaces genéricas. Otro caso interesante es el checklist de revisión de gstack, con más de 200 líneas de patrones concretos y una sección de supresiones para evitar falsos positivos. Y si buscas el referente más completo de este patrón, las agent-skills de Addy Osmani incluyen tablas de anti-racionalizaciones en cada una de sus 19 skills: excusas documentadas que el agente usa para saltarse pasos, con la réplica que le obliga a seguir el proceso.
⚠️ Si tu skill no tiene una sección de “NUNCA”, probablemente le falta la mitad del conocimiento experto.
5. Estructura tu skill en capas ¶
Un skill no debería cargar toda su información de golpe. El contexto del agente es un recurso compartido entre el sistema, la conversación, otros skills y la petición del usuario. Cada token cuenta.
La estructura ideal tiene tres capas:
- Metadatos (~100 tokens): nombre y descripción. Se cargan siempre para todos los skills.
- Instrucciones (<5000 tokens): el cuerpo del SKILL.md. Se carga cuando se activa el skill.
- Recursos (según necesidad): archivos en
scripts/,references/,assets/. Se cargan bajo demanda.
❌ Todo en un solo archivo ¶
mi-skill/
└── SKILL.md (800 líneas con todo incluido)
Esto fuerza al agente a cargar 800 líneas cada vez que activa el skill, aunque solo necesite una parte.
✅ Estructura con carga progresiva ¶
mi-skill/
├── SKILL.md (150 líneas: routing y decisiones)
├── references/
│ ├── api-details.md (documentación técnica detallada)
│ └── examples.md (ejemplos extensos)
└── scripts/
└── process.py (script ejecutable)
Pero no basta con separar los archivos. Necesitas decirle al agente CUÁNDO cargar cada uno. Un ejemplo bien resuelto de este patrón es Visual Explainer, que mantiene un SKILL.md ligero con el workflow principal y delega CSS, librerías, plantillas y patrones de slides a archivos references/ que el agente solo lee cuando la tarea concreta lo necesita.
❌ Referencias listadas sin triggers ¶
## Referencias
- api-details.md - para detalles de la API
- examples.md - para ver ejemplos
El agente no sabe cuándo cargar estos archivos. Probablemente nunca lo haga.
✅ Triggers de carga integrados en el workflow ¶
## Crear documento nuevo
**OBLIGATORIO - LEE EL ARCHIVO COMPLETO**: Antes de continuar, DEBES leer
[`references/docx-structure.md`](references/docx-structure.md) (~300 líneas)
de principio a fin. NO establezcas límites de rango al leer.
**NO cargues** `references/redlining.md` ni `references/forms.md` para esta tarea.
## Editar documento existente con cambios registrados
**OBLIGATORIO**: Lee [`references/redlining.md`](references/redlining.md) antes
de hacer cualquier modificación.
La diferencia está en dos elementos clave:
- Triggers obligatorios: “DEBES leer X antes de Y”
- Indicaciones de qué NO cargar: evita que el modelo cargue información irrelevante
6. Ajusta la libertad según la fragilidad de la tarea ¶
No todas las tareas necesitan el mismo nivel de detalle en las instrucciones. Una tarea creativa se beneficia de principios amplios. Una tarea técnica delicada necesita pasos exactos.
La regla es simple: cuanto más grave sea el error, menos libertad debe tener el modelo.
❌ Libertad mal calibrada ¶
## Diseño de interfaz (tarea creativa)
1. Abre Figma
2. Crea un frame de 1920x1080
3. Añade un rectángulo de 200x50 para el botón
4. Usa color #3B82F6 para el fondo
5. Añade texto "Enviar" centrado
Esto es demasiado rígido para una tarea creativa. No deja espacio para diferenciación.
## Edición de archivos XLSX (tarea frágil)
Modifica las celdas según sea necesario. Ten cuidado con los formatos.
Esto es demasiado vago para una tarea donde un error corrompe el archivo.
✅ Libertad calibrada correctamente ¶
## Diseño de interfaz (alta libertad)
Comprométete con una dirección estética AUDAZ. Elige un extremo:
minimalismo brutal, caos maximalista, retro-futurista, orgánico natural...
Principios a mantener:
- Jerarquía visual clara (qué ve primero el usuario)
- Contraste suficiente para legibilidad
- Consistencia interna (si empiezas rounded, mantén rounded)
NUNCA: diseño genérico que podría ser de cualquier web SaaS.
## Edición de archivos XLSX (baja libertad)
**USA EXACTAMENTE este script**: `scripts/edit-xlsx.py`
Parámetros obligatorios:
- `--input`: archivo original
- `--output`: archivo destino (NUNCA sobrescribas el original)
- `--changes`: JSON con modificaciones
**NUNCA modifiques el script.** Si necesitas funcionalidad adicional,
crea un script nuevo basado en este.
Después de cada edición:
1. Abre el archivo en Excel/LibreCalc
2. Verifica que las fórmulas recalculan
3. Comprueba que no hay #REF! ni #VALUE!
La tarea creativa recibe principios y anti-patrones. La tarea frágil recibe scripts exactos y verificaciones obligatorias.
7. Incluye árboles de decisión para caminos múltiples ¶
Cuando una tarea tiene varios caminos posibles, el modelo necesita saber cómo elegir. Un simple “usa la herramienta apropiada” no sirve. Necesita criterios concretos.
❌ Guía vaga ¶
## Procesamiento de imágenes
Usa la herramienta más apropiada para cada caso. Considera el formato
de entrada y la salida deseada.
✅ Árbol de decisión explícito ¶
## Procesamiento de imágenes: árbol de decisión
¿La imagen es vectorial (SVG)?
├── SÍ → Usa Inkscape CLI para transformaciones
│ inkscape --export-type=png input.svg
└── NO → ¿Necesitas preservar transparencia?
├── SÍ → Usa PNG como formato intermedio
│ ImageMagick: convert input.jpg -alpha set output.png
└── NO → ¿Es fotografía o ilustración?
├── Fotografía → JPEG con calidad 85
│ convert input.png -quality 85 output.jpg
└── Ilustración → PNG-8 con paleta reducida
pngquant --quality=65-80 input.png
### Fallbacks para cuando falla el camino principal
| Operación | Herramienta primaria | Fallback | Señal para cambiar |
| ---------------- | -------------------- | ----------- | -------------------------- |
| Redimensionar | ImageMagick | PIL/Pillow | ImageMagick no instalado |
| Comprimir PNG | pngquant | optipng | pngquant produce artifacts |
| Convertir a WebP | cwebp | ImageMagick | cwebp no soporta animación |
El árbol de decisión elimina la ambigüedad. El modelo sabe exactamente qué preguntas hacerse y qué camino tomar según las respuestas.
8. Proporciona ejemplos que funcionen ¶
Parece obvio, pero muchos skills incluyen pseudocódigo o ejemplos incompletos que el modelo no puede ejecutar directamente.
❌ Ejemplo incompleto ¶
# Procesa el archivo
result = process(input_file)
# Guarda el resultado
save(result)
¿Qué es process? ¿De dónde viene save? El modelo tiene que inventar estas funciones.
✅ Ejemplo ejecutable ¶
import json
from pathlib import Path
def extract_metadata(pdf_path: str) -> dict:
"""
Extrae metadatos de un PDF usando PyMuPDF.
Retorna dict con título, autor, fecha de creación.
"""
import fitz # PyMuPDF
doc = fitz.open(pdf_path)
metadata = doc.metadata
doc.close()
return {
"title": metadata.get("title", "Sin título"),
"author": metadata.get("author", "Desconocido"),
"created": metadata.get("creationDate", ""),
"pages": doc.page_count
}
# Uso
if __name__ == "__main__":
result = extract_metadata("documento.pdf")
print(json.dumps(result, indent=2, ensure_ascii=False))
El ejemplo incluye imports, manejo de casos donde faltan datos, y un bloque de uso directo. El modelo puede copiarlo y adaptarlo sin tener que adivinar piezas faltantes.
🛠️ Cada ejemplo de código en tu skill debería poder ejecutarse sin modificaciones. Si no es así, es pseudocódigo disfrazado.
9. Maneja los errores antes de que ocurran ¶
Un skill robusto anticipa qué puede salir mal y proporciona soluciones. No espera a que el modelo se quede atascado.
❌ Sin manejo de errores ¶
## Extracción de texto
Ejecuta pdftotext sobre el archivo y procesa el resultado.
¿Y si el PDF está encriptado? ¿Y si está escaneado? ¿Y si el archivo está corrupto?
✅ Con anticipación de problemas ¶
## Extracción de texto: problemas comunes
### PDF devuelve texto vacío
- **Causa probable**: PDF escaneado (imágenes, no texto)
- **Solución**: Aplica OCR primero con Tesseract
```bash
pdftoppm -png documento.pdf temp
tesseract temp-1.png output -l spa
Error de permisos ¶
- Causa probable: PDF encriptado o con restricciones
- Solución: Usa PyMuPDF con contraseña si la conoces
doc = fitz.open("documento.pdf") if doc.needs_pass: doc.authenticate("contraseña") - Si no hay contraseña: Informa al usuario que el PDF tiene restricciones
Texto extraído con caracteres raros ¶
- Causa probable: Encoding incorrecto o fuentes embebidas no estándar
- Solución: Prueba con diferentes backends
- Primero pdftotext (más rápido)
- Si falla, PyMuPDF (mejor con fuentes raras)
- Último recurso: OCR sobre renderizado
## 10. El nombre del skill también importa
No tanto como la descripción, pero un nombre claro ayuda a identificar el propósito del skill de un vistazo.
### ❌ Nombres problemáticos
```yaml
name: helper # Demasiado genérico
name: MyAwesomeTool # Mayúsculas no permitidas
name: doc_processor # Guiones bajos no permitidos
name: -pdf-tool # No puede empezar con guión
✅ Nombres correctos ¶
name: pdf-extraction
name: docx-formatting
name: image-optimization
name: api-integration
Las reglas son simples: minúsculas, números y guiones. Sin guiones al principio o final. Sin guiones consecutivos. Máximo 64 caracteres.
Resumen: los 3 consejos fundamentales ¶
Después de todo lo que hemos visto, si tuviera que quedarme con tres ideas clave serían estas:
1. La descripción es tu única oportunidad ¶
El agente decide qué skill activar basándose solo en las descripciones. Tu skill puede ser perfecto, pero si la descripción no responde QUÉ hace, CUÁNDO usarlo y con qué PALABRAS CLAVE se relaciona, nunca se activará. Invierte tiempo en escribir una descripción completa y específica.
2. Aporta conocimiento que Claude no tiene ¶
No expliques conceptos básicos. No hagas tutoriales de librerías estándar. No repitas lo que está en cualquier documentación. Tu skill debe contener decisiones de experto, trade-offs, casos límite, anti-patrones específicos. Todo lo demás es ruido que consume tokens sin aportar valor.
3. Estructura para carga progresiva ¶
Mantén el SKILL.md principal por debajo de 500 líneas. Mueve el contenido detallado a archivos de referencia. Incluye triggers explícitos que digan cuándo cargar cada recurso y cuándo NO hacerlo. El contexto del agente es limitado y compartido.
Aplica estos tres principios y tus skills pasarán de ser decoración a herramientas que transforman cómo el agente aborda los problemas. Y si quieres ir un paso más allá y validar con datos que tu skill realmente aporta valor, skill-creator te permite evaluar con subagentes paralelos y benchmarks reales. Y si te interesa ver cómo se aplica TDD a la creación de las propias skills, en el análisis del framework Superpowers detallamos cómo su skill writing-skills valida cada skill con subagentes antes de darla por buena. Para ver el enfoque opuesto —skills que invierten el flujo y ponen al agente a interrogarte a ti— echa un ojo a /grill-me y las 11 skills hermanas del repo de Matt Pocock. Y cuando tu skill esté lista para que la use más gente, publicarla en el registro es tan simple como subirla a un repo público: ni formularios ni colas de revisión.


Escrito con la ayuda de la IA generativa de Claude, fuentes fidedignas y con un human in the loop:
Dani Primo.
12 recursos para developers cada domingo en tu bandeja de entrada
Además de una skill práctica bien explicada, trucos para mejorar tu futuro profesional y una pizquita de humor útil para el resto de la semana. Gratis.