Aprende Laravel AI SDK para crear un asistente personal con RAG
He montado un asistente personal con Laravel AI SDK que busca en mi propia documentación, recuerda las conversaciones y responde por la terminal o desde el navegador. Y funciona.
No es un tutorial teórico. Es el recorrido real, paso a paso, de un proyecto que he construido desde composer create-project hasta una pregunta en la terminal que devuelve una respuesta con contexto extraído de mis propios archivos markdown.
Esto es lo que vas a encontrar aquí:
- Instalación del SDK y sus dependencias
- Creación de un agente con memoria conversacional
- Un sistema RAG completo con búsqueda vectorial sin PostgreSQL
- Ingesta de documentación con un comando Artisan
- Chat por terminal y por web con streaming
- Los tropezones reales que me he encontrado por el camino
Vamos al lío.
El stack del proyecto ¶
Antes de meternos en harina, un vistazo rápido a las piezas que forman el proyecto:
🧨 Última oprtunidad para recibir la dinamita que mereces sobre programación con IA el próximo domingo: Suscríbete gratis a Web Reactiva en https://webreactiva.com/newsletter
- Laravel 12 — el framework base, con SQLite por defecto
- laravel/ai (v0.1.3) — el SDK oficial de IA de Laravel. Gestiona agentes, tools, memoria conversacional, streaming y testing. Trae como dependencia
prism-php/prism, el motor que se comunica con los proveedores de IA, yopenai-php/client - theodo-group/llphant (v0.11.12) — librería PHP para IA generativa que nosotros añadimos al proyecto. La usamos por su
FileSystemVectorStore, que permite almacenar embeddings en un fichero JSON y hacer búsqueda por similitud sin necesidad de base de datos vectorial - OpenAI como proveedor — tanto para el agente (generación de texto) como para los embeddings (modelo
text-embedding-3-small). El SDK soporta también Anthropic, Gemini, Groq, xAI, DeepSeek, Mistral y Ollama
Y esta es la arquitectura del sistema:

Si quieres el resumen ejecutivo: Laravel AI SDK + LLPhant + SQLite + un par de comandos Artisan = un asistente personal con RAG que funciona en local sin infraestructura extra.
Qué necesitas antes de empezar ¶
Laravel AI SDK funciona sobre Laravel 12.x y requiere PHP 8.4 como mínimo. Ojo con esto: Laravel 12 acepta PHP 8.2, pero laravel/ai sube el listón a 8.4. Si tu entorno no está actualizado, te encontrarás con un error de Composer antes de escribir una sola línea.
Lo que necesitas:
- PHP 8.4 o superior
- Composer
- Una API key de OpenAI
- SQLite (viene por defecto con Laravel 12, no necesitas PostgreSQL)
🔑 Crea las API keys con permisos restringidos. No uses tu clave de administración para un proyecto de pruebas. Es una buena costumbre que cuesta cero euros.
Instalación paso a paso ¶
Crear el proyecto ¶
composer create-project laravel/laravel mi-asistente --prefer-dist
cd mi-asistente
Laravel crea la aplicación con SQLite por defecto, genera la APP_KEY, ejecuta las migraciones base y te deja listo para trabajar.
Instalar las dependencias ¶
composer require laravel/ai theodo-group/llphant
Con este comando instalas el SDK oficial y la librería LLPhant. El SDK se trae por debajo prism-php/prism y openai-php/client como dependencias propias.
Atención: el nombre del paquete de LLPhant en Packagist es theodo-group/llphant, no llphant/llphant. Es un error fácil de cometer.
Publicar configuración y migraciones ¶
php artisan vendor:publish --provider="Laravel\Ai\AiServiceProvider"
php artisan migrate
El vendor:publish copia a tu proyecto:
config/ai.php— configuración de proveedores, modelos por defecto y caché de embeddings- Migraciones para las tablas
agent_conversationsyagent_conversation_messages - Stubs para generar agentes y tools con
make:agentymake:tool
La migración crea la estructura que el SDK necesita para almacenar conversaciones. Cada mensaje guarda el rol (user/assistant), el contenido, las llamadas a tools, los resultados, los tokens consumidos y metadatos. Todo en SQLite, sin complicaciones.
Cada semana, experiencias y aprendizaje sobre desarrollo web e IA en tu bandeja de entrada.
Únete a más de 6.700 developers que ya reciben la newsletter.
Suscríbete gratis →Configurar las variables de entorno ¶
Aquí viene un detalle que me hizo perder unos minutos. El .env.example de Laravel no incluye las variables de IA. El fichero sigue siendo el estándar del framework, sin OPENAI_API_KEY ni ninguna otra clave de proveedor. Pero si miras config/ai.php, verás que el proyecto depende de esas variables:
'openai' => [
'driver' => 'openai',
'key' => env('OPENAI_API_KEY'),
],
Así que tienes que añadirlas tú a mano en .env:
OPENAI_API_KEY=sk-tu-clave-aqui
Y si vas a compartir el proyecto con tu equipo, actualiza también .env.example para que nadie se quede colgado preguntándose por qué el agente devuelve errores de autenticación.
⚠️ No olvides añadir
OPENAI_API_KEY(o la clave de tu proveedor) al.env.example. Laravel no lo hace por ti y tu equipo te lo agradecerá.
El proveedor por defecto en config/ai.php es openai. En este proyecto lo usamos tanto para el agente (texto) como para generar los embeddings de la documentación.
El agente: PersonalAssistant ¶
Un agente en Laravel AI SDK es una clase PHP que encapsula instrucciones, contexto conversacional, herramientas y configuración. Puedes crearlo con php artisan make:agent o a mano. Yo fui directo al fichero.
Fichero: app/Ai/Agents/PersonalAssistant.php
<?php
namespace App\Ai\Agents;
use App\Ai\Tools\SearchKnowledgeBase;
use Laravel\Ai\Attributes\MaxSteps;
use Laravel\Ai\Attributes\MaxTokens;
use Laravel\Ai\Attributes\Provider;
use Laravel\Ai\Attributes\Temperature;
use Laravel\Ai\Attributes\Timeout;
use Laravel\Ai\Concerns\RemembersConversations;
use Laravel\Ai\Contracts\Agent;
use Laravel\Ai\Contracts\Conversational;
use Laravel\Ai\Contracts\HasTools;
use Laravel\Ai\Promptable;
use Laravel\Ai\Providers\Tools\WebSearch;
#[Provider('openai')]
#[MaxSteps(8)]
#[MaxTokens(4096)]
#[Temperature(0.7)]
#[Timeout(120)]
class PersonalAssistant implements Agent, Conversational, HasTools
{
use Promptable, RemembersConversations;
public function instructions(): string
{
return <<<'PROMPT'
You are a helpful personal assistant specialized in
Laravel AI SDK and modern web development.
When the user asks about these topics, ALWAYS use
the SearchKnowledgeBase tool first to find relevant
documentation before answering.
Use web search when the user asks about current events
or information not in your knowledge base.
Answer clearly, be concise, and always be honest
about what you don't know.
Respond in the same language the user writes to you.
PROMPT;
}
/**
* @return \Laravel\Ai\Contracts\Tool[]
*/
public function tools(): iterable
{
return [
new SearchKnowledgeBase,
(new WebSearch)->max(5),
];
}
}
Vamos a desmenuzar las piezas.
Las interfaces importan ¶
El agente implementa tres interfaces:
Agent: la base. Sin esto no tienes agente.Conversational: permite mantener un hilo de conversación con historial. Sin ella, cada prompt sería una interacción aislada.HasTools: le dice al SDK que este agente tiene herramientas disponibles. Esto es crítico: si defines un métodotools()pero no implementasHasTools, el runtime ignora tus herramientas. El método existe, pero nadie lo llama. Una trampa silenciosa.
Los traits que hacen el trabajo pesado ¶
Promptable: te da los métodosprompt(),stream(),queue()ymake(). Es lo que convierte la clase en algo que puedes invocar.RemembersConversations: gestiona la persistencia del historial. Guarda mensajes en la base de datos y los carga cuando retomas una conversación concontinue().
Atributos PHP para la configuración ¶
En vez de ficheros de config o métodos sueltos, el SDK usa atributos PHP:
#[Provider('openai')]— proveedor de IA#[MaxSteps(8)]— cuántas veces puede encadenar llamadas a tools#[MaxTokens(4096)]— límite de tokens en la respuesta#[Temperature(0.7)]— equilibrio entre precisión y creatividad#[Timeout(120)]— 2 minutos de timeout, generoso para cuando el agente busca en la web
Las instrucciones: el alma del agente ¶
El prompt de sistema le dice al agente qué hacer y cómo hacerlo. Fíjate en que le pido buscar primero en la knowledge base antes de responder. Esto no es decorativo: sin esa instrucción, el modelo puede ignorar la herramienta y responder de memoria, que es justo lo que no quieres en un sistema RAG.
También le indico que responda en el idioma del usuario. Sin esto, un agente con instrucciones en inglés tiende a responder en inglés aunque le preguntes en español.
Una nota sobre la memoria ¶
El trait RemembersConversations es cómodo, pero tiene un matiz: que los mensajes estén guardados en la base de datos no significa que el modelo los vea todos. Los proveedores tienen un límite de ventana de contexto (tokens). Si la conversación crece mucho, los mensajes más antiguos quedarán fuera de lo que el modelo procesa. Para conversaciones largas, considera limitar el número de mensajes o resumir el historial.
💡 La memoria conversacional es la diferencia entre un chatbot de usar y tirar y un asistente que merece la pena. Pero memoria en base de datos no es memoria infinita para el modelo.
El sistema RAG: búsqueda en tu propia documentación ¶
Aquí es donde la cosa se pone interesante. El asistente no solo habla con un modelo: busca en tus documentos antes de responder.
Por qué LLPhant y no pgvector ¶
Para la búsqueda vectorial hay muchas opciones: PostgreSQL con pgvector (que el propio SDK de Laravel soporta de forma nativa), bases de datos especializadas como Pinecone o Weaviate, o soluciones más ligeras.
Nosotros elegimos LLPhant y su FileSystemVectorStore porque es la opción más sencilla para empezar. Almacena los embeddings en un fichero JSON y hace la búsqueda por similitud en memoria. No necesitas instalar extensiones, levantar servicios adicionales ni configurar una base de datos vectorial.
¿Es la solución para producción con millones de documentos? No. ¿Es perfecta para arrancar, para prototipos y para proyectos pequeños? Sin duda. Cuando necesites escalar, el salto a pgvector o a un servicio dedicado es un cambio en la capa de almacenamiento, no una reescritura del sistema.
La herramienta SearchKnowledgeBase ¶
Fichero: app/Ai/Tools/SearchKnowledgeBase.php
<?php
namespace App\Ai\Tools;
use Illuminate\Contracts\JsonSchema\JsonSchema;
use Laravel\Ai\Contracts\Tool;
use Laravel\Ai\Tools\Request;
use LLPhant\Embeddings\EmbeddingGenerator\OpenAI\OpenAI3SmallEmbeddingGenerator;
use LLPhant\Embeddings\VectorStores\FileSystem\FileSystemVectorStore;
use LLPhant\OpenAIConfig;
use Stringable;
class SearchKnowledgeBase implements Tool
{
public function description(): Stringable|string
{
return 'Search the knowledge base for relevant documentation '
. 'based on a query. Use this tool when the user asks '
. 'about Laravel AI SDK, agents, tools, embeddings, '
. 'streaming, testing, or anything related to the '
. 'documented topics.';
}
public function handle(Request $request): Stringable|string
{
$config = new OpenAIConfig();
$config->apiKey = config('services.openai.key', env('OPENAI_API_KEY'));
$embeddingGenerator = new OpenAI3SmallEmbeddingGenerator($config);
$vectorStore = new FileSystemVectorStore(
storage_path('vectorstore/knowledge-base.json')
);
// Generar el embedding de la consulta del usuario
$queryEmbedding = $embeddingGenerator->embedText($request['query']);
// Buscar los chunks más similares
$results = $vectorStore->similaritySearch(
$queryEmbedding,
$request['limit'] ?? 5
);
if (empty($results)) {
return 'No relevant documents found for this query.';
}
$output = [];
foreach ($results as $doc) {
$source = $doc->sourceName !== 'manual'
? "[Source: {$doc->sourceName}]"
: '';
$output[] = "{$source}\n{$doc->content}";
}
return implode("\n\n---\n\n", $output);
}
public function schema(JsonSchema $schema): array
{
return [
'query' => $schema->string()->required(),
'limit' => $schema->integer()->min(1)->max(10),
];
}
}
El flujo es este:
- El agente decide que necesita buscar información y llama a
SearchKnowledgeBase - La herramienta genera un embedding de la pregunta del usuario con
text-embedding-3-smallde OpenAI (1536 dimensiones) - Ejecuta
similaritySearch()contra el fichero JSON del vector store - Devuelve los chunks más similares al agente, que los usa como contexto para su respuesta
Todo sin PostgreSQL, sin pgvector, sin infraestructura extra. El fichero storage/vectorstore/knowledge-base.json es tu “base de datos vectorial”.
El comando de ingesta ¶
Para que la búsqueda funcione, primero necesitas alimentar el vector store con tus documentos. Creé un comando Artisan que lee todos los archivos .md de la carpeta docs/ del proyecto y los procesa.
Fichero: app/Console/Commands/IngestDocumentation.php
<?php
namespace App\Console\Commands;
use Illuminate\Console\Command;
use LLPhant\Embeddings\Document;
use LLPhant\Embeddings\EmbeddingGenerator\OpenAI\OpenAI3SmallEmbeddingGenerator;
use LLPhant\Embeddings\VectorStores\FileSystem\FileSystemVectorStore;
use LLPhant\OpenAIConfig;
class IngestDocumentation extends Command
{
protected $signature = 'docs:ingest {--fresh : Clear existing vector store}';
protected $description = 'Ingest markdown docs into the vector store';
public function handle(): int
{
$docsPath = base_path('docs');
$storePath = storage_path('vectorstore/knowledge-base.json');
$files = glob($docsPath . '/*.md');
if (empty($files)) {
$this->error('No markdown files found in docs/');
return self::FAILURE;
}
if ($this->option('fresh') && file_exists($storePath)) {
unlink($storePath);
$this->info('Cleared existing vector store.');
}
$config = new OpenAIConfig;
$config->apiKey = config('services.openai.key', env('OPENAI_API_KEY'));
$embeddingGenerator = new OpenAI3SmallEmbeddingGenerator($config);
$vectorStore = new FileSystemVectorStore($storePath);
$this->info('Ingesting ' . count($files) . ' documentation file(s)...');
$totalChunks = 0;
foreach ($files as $file) {
$filename = basename($file);
$content = file_get_contents($file);
$chunks = $this->chunkBySection($content);
$this->info(" {$filename}: " . count($chunks) . ' chunks');
$documents = [];
foreach ($chunks as $index => $chunk) {
$doc = new Document;
$doc->content = $chunk;
$doc->sourceType = 'documentation';
$doc->sourceName = $filename;
$doc->chunkNumber = $index;
$doc->hash = md5($chunk);
$documents[] = $doc;
}
$this->info(' Generating embeddings...');
$embeddedDocs = $embeddingGenerator->embedDocuments($documents);
$vectorStore->addDocuments($embeddedDocs);
$totalChunks += count($chunks);
}
$this->info("Done! Ingested {$totalChunks} chunks into {$storePath}");
return self::SUCCESS;
}
/**
* Divide el contenido markdown por secciones ##
* @return string[]
*/
private function chunkBySection(string $content): array
{
$sections = preg_split('/^(?=## )/m', $content);
$chunks = [];
foreach ($sections as $section) {
$section = trim($section);
if ($section === '') continue;
if (mb_strlen($section) > 3000) {
foreach ($this->splitLargeSection($section) as $sub) {
$chunks[] = $sub;
}
} else {
$chunks[] = $section;
}
}
return $chunks;
}
/**
* Subdivide secciones grandes en ~1500 caracteres
* por límites de párrafo
* @return string[]
*/
private function splitLargeSection(string $section): array
{
$paragraphs = preg_split('/\n{2,}/', $section);
$chunks = [];
$current = '';
foreach ($paragraphs as $paragraph) {
if (mb_strlen($current) + mb_strlen($paragraph) > 1500
&& $current !== '') {
$chunks[] = trim($current);
$current = $paragraph;
} else {
$current .= "\n\n" . $paragraph;
}
}
if (trim($current) !== '') {
$chunks[] = trim($current);
}
return $chunks;
}
}
La idea es sencilla: el comando busca todos los .md que haya en docs/, los trocea por secciones de encabezado ## y, si alguna sección supera los 3000 caracteres, la subdivide en bloques de ~1500 por límites de párrafo. Después genera los embeddings con OpenAI y los almacena en el fichero JSON.
En nuestro caso, la carpeta docs/ contenía la propia documentación del Laravel AI SDK (ai.md) y el borrador de este post (post.md). Así que el asistente se convirtió en un experto sobre sí mismo. Meta, pero útil.
php artisan docs:ingest --fresh
Ingesting 2 documentation file(s)...
ai.md: 42 chunks
Generating embeddings...
post.md: 19 chunks
Generating embeddings...
Done! Ingested 61 chunks into storage/vectorstore/knowledge-base.json
61 chunks, un fichero JSON de 1.6 MB y ya tienes tu vector store listo. Cada vez que actualices la documentación, vuelves a ejecutar el comando con --fresh y resuelto.
Puedes meter en esa carpeta lo que quieras: documentación de tu API, guías internas del equipo, notas de producto, actas de reuniones… Todo lo que sea markdown y quieras que tu asistente pueda consultar.
📂 La carpeta
docs/es tu knowledge base. Mete ahí los markdowns que quieras que tu asistente conozca y ejecutadocs:ingest. Así de simple.
Dos formas de hablar con el asistente ¶
Por terminal: el comando assistant:chat ¶
Fichero: app/Console/Commands/ChatWithAssistant.php
<?php
namespace App\Console\Commands;
use App\Ai\Agents\PersonalAssistant;
use App\Models\User;
use Illuminate\Console\Command;
class ChatWithAssistant extends Command
{
protected $signature = 'assistant:chat
{--conversation= : Resume a previous conversation by ID}';
protected $description = 'Chat with the PersonalAssistant from the terminal';
public function handle(): int
{
$user = User::first() ?? $this->createDefaultUser();
$conversationId = $this->option('conversation');
$this->info('Personal Assistant (type "exit" to quit)');
$this->info('=========================================');
if ($conversationId) {
$this->info("Resuming conversation: {$conversationId}");
}
$this->newLine();
while (true) {
$message = $this->ask('You');
if ($message === null
|| strtolower(trim($message)) === 'exit') {
$this->info('Bye!');
return self::SUCCESS;
}
if (trim($message) === '') continue;
try {
$agent = new PersonalAssistant;
if ($conversationId) {
$response = $agent
->continue($conversationId, as: $user)
->prompt($message);
} else {
$response = $agent
->forUser($user)
->prompt($message);
$conversationId = $response->conversationId;
$this->line(
"<fg=gray>Conversation ID: {$conversationId}</>"
);
}
$this->newLine();
$this->line("<fg=cyan>Assistant:</> {$response}");
$this->newLine();
} catch (\Throwable $e) {
$this->error("Error: {$e->getMessage()}");
$this->newLine();
}
}
}
private function createDefaultUser(): User
{
return User::create([
'name' => 'CLI User',
'email' => 'cli@assistant.local',
'password' => bcrypt('password'),
]);
}
}
Así lo usas:
# Nueva conversación
php artisan assistant:chat
# Retomar una conversación anterior
php artisan assistant:chat --conversation=019c3de1-de76-73cd-a11a-600d4f5d8706
El loop es simple: pregunta, respuesta, pregunta. Escribe exit para salir. Si es la primera vez, crea un usuario por defecto en la base de datos (necesario para RemembersConversations) y te muestra el ID de la conversación para retomarla más tarde.
Un detalle que me gusta: el try-catch envuelve cada interacción, no el loop completo. Si una llamada falla (timeout, rate limit, error del proveedor), el chat muestra el error y te deja seguir preguntando sin perder la sesión.
Por web: streaming con SSE ¶
Fichero: app/Http/Controllers/AssistantController.php
<?php
namespace App\Http\Controllers;
use App\Ai\Agents\PersonalAssistant;
use Illuminate\Http\Request;
class AssistantController extends Controller
{
public function index()
{
return view('assistant');
}
public function start(Request $request)
{
$request->validate([
'message' => 'required|string|max:2000',
]);
return (new PersonalAssistant)
->forUser($request->user())
->stream($request->input('message'));
}
public function reply(Request $request, string $conversationId)
{
$request->validate([
'message' => 'required|string|max:2000',
]);
return (new PersonalAssistant)
->continue($conversationId, as: $request->user())
->stream($request->input('message'));
}
}
Las rutas:
// routes/web.php
Route::get('/assistant', [AssistantController::class, 'index']);
Route::post('/assistant', [AssistantController::class, 'start']);
Route::post('/assistant/{conversationId}', [AssistantController::class, 'reply']);
El método stream() devuelve una respuesta SSE (Server-Sent Events) que el frontend consume en tiempo real. La vista es HTML con JavaScript vanilla que lee el stream y va pintando el texto a medida que llega. Nada de frameworks de frontend, nada de dependencias extra.
🚀 El streaming marca la diferencia entre una experiencia que parece muerta (8 segundos de pantalla en blanco) y una que fluye. En la terminal usamos
prompt()porque no hay interfaz visual que beneficiar. En la web,stream()siempre.
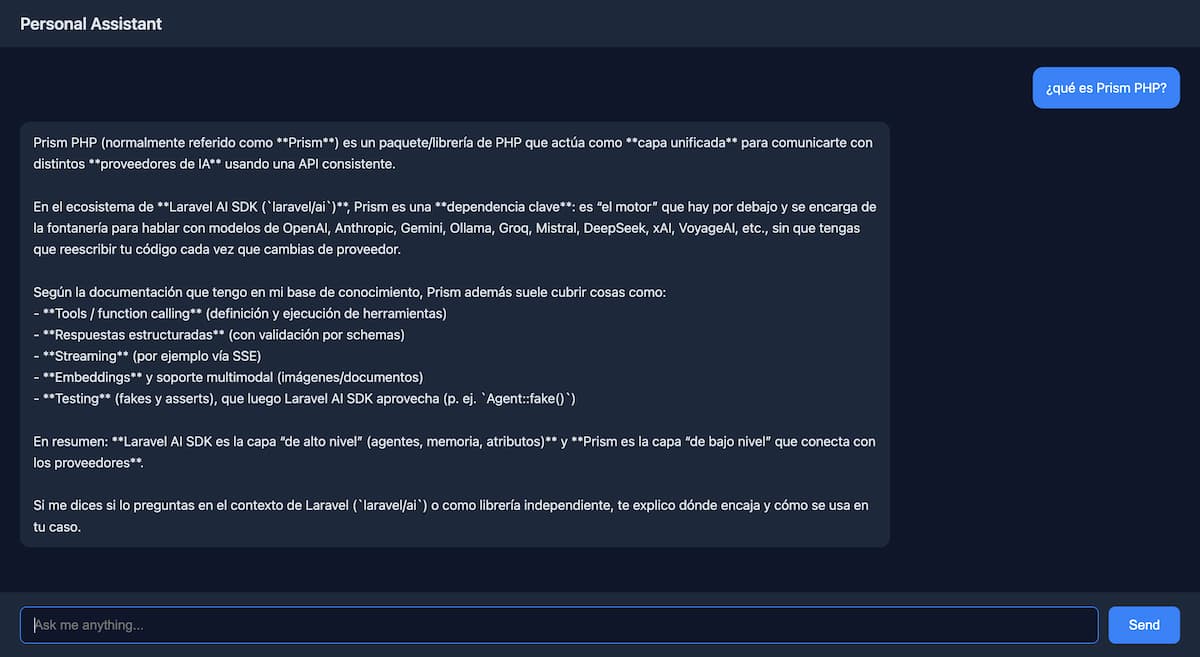
La verificación: esto funciona ¶
Después de montar todo, ejecuté una prueba real:
php artisan assistant:chat
Personal Assistant (type "exit" to quit)
=========================================
You:
> ¿Qué es el Laravel AI SDK?
Conversation ID: 019c3de1-de76-73cd-a11a-600d4f5d8706
El asistente usó la herramienta SearchKnowledgeBase, encontró chunks relevantes de la documentación y respondió en español con información precisa extraída de los ficheros que había ingerido.
No respondió “de memoria”. Buscó, encontró y contextualizó. Eso es RAG funcionando.
Prism y LLPhant: las librerías que hacen posible la magia ¶
Ahora que has visto el proyecto completo, vale la pena entender un poco mejor las dos piezas clave que hay por debajo.
Prism: la fontanería del SDK ¶
Cuando instalas laravel/ai, una de sus dependencias es Prism, creada por TJ Miller. Es el motor que se comunica con los proveedores de IA.
Prism nació como un paquete independiente inspirado en el Vercel AI SDK, adaptado al ecosistema Laravel. Ofrece una interfaz unificada para hablar con OpenAI, Anthropic, Gemini, Ollama y el resto de proveedores. Lo que aporta va más allá de ser un cliente HTTP: gestiona el sistema de tools, la generación de respuestas estructuradas con validación de schemas, el streaming con SSE, los embeddings y el soporte multimodal. También trae su propio sistema de testing con fakes y asserts, que es la base del Agent::fake().
Dicho de otro modo: laravel/ai es la capa de alto nivel con agentes, memoria y atributos PHP. Prism es la fontanería que hace que los datos fluyan. No necesitas usar Prism de forma directa (el SDK lo abstrae), pero saber que existe te ayuda a entender qué pasa cuando algo falla.
LLPhant: embeddings sin infraestructura ¶
LLPhant es una librería PHP para IA generativa con herramientas para generación de texto, embeddings, búsqueda vectorial y cadenas RAG. Nosotros la añadimos al proyecto por su FileSystemVectorStore, pero ofrece mucho más: conectores para Elasticsearch, Milvus, ChromaDB, y generadores de embeddings para varios proveedores.
Lo interesante es que el FileSystemVectorStore es una implementación completa de búsqueda vectorial por similitud coseno. No es un mock ni un placeholder: funciona. La limitación es el rendimiento cuando el volumen de datos crece, porque carga todo el fichero JSON en memoria. Para 61 chunks como los nuestros, es instantáneo. Para 100.000, busca otra solución.
Laravel Boost: MCP para desarrollo con IA ¶
Como parte del setup del proyecto, también instalé Laravel Boost, la herramienta MCP (Model Context Protocol) de Laravel para desarrollo asistido por IA. No es parte del asistente en sí, pero configura guidelines y servidores MCP para Cursor, Claude Code, Codex, OpenCode y Gemini CLI en un solo comando.
Testing: no dejes esto para después ¶
El SDK trae un sistema de testing que te permite simular respuestas sin hacer llamadas reales a la API:
use App\Ai\Agents\PersonalAssistant;
use Laravel\Ai\Prompts\AgentPrompt;
// Simular respuestas
PersonalAssistant::fake([
'El Laravel AI SDK es un paquete para integrar IA en Laravel.',
]);
// Ejecutar tu lógica
$response = (new PersonalAssistant)->prompt('¿Qué es Laravel AI SDK?');
// Verificar la llamada
PersonalAssistant::assertPrompted(function (AgentPrompt $prompt) {
return str_contains($prompt->prompt, 'Laravel AI SDK');
});
Y si quieres que ningún test escape sin mock:
PersonalAssistant::fake()->preventStrayPrompts();
Esto lanza una excepción si algún test invoca el agente sin respuesta preparada. No gastas tokens, no dependes de servicios externos y tus tests pasan en milisegundos.
✅ Escribe tests desde el primer día. Con
fake()no tienes excusa. Dormir tranquilo es un superpoder infravalorado.
Lo que he aprendido montando esto ¶
-
PHP 8.4 es obligatorio. El composer.json de
laravel/ailo exige. Si tu servidor o tu CI está en 8.2 o 8.3, no arranca. Compruébalo antes de empezar. -
El
.env.exampleno te ayuda. Las variables de los proveedores de IA no vienen incluidas. Añádelas desde el minuto cero o tu equipo perderá tiempo innecesario. -
HasToolsno es opcional. Si definestools()pero no implementas la interfazHasTools, el SDK ignora tus herramientas. Error silencioso. -
Las instrucciones del agente determinan si usa las tools. Sin “ALWAYS use SearchKnowledgeBase first”, el modelo puede decidir responder de memoria. Sé explícito.
-
LLPhant con FileSystemVectorStore es viable para empezar. Un fichero JSON y búsqueda en memoria funcionan bien para prototipos y proyectos pequeños. Cuando escales, el cambio es en la capa de almacenamiento.
-
El chunking importa. Dividir por
##y subdividir secciones grandes da resultados decentes. Pero si tus documentos tienen otra estructura, ajusta la estrategia. -
La memoria conversacional tiene límite.
RemembersConversationsguarda todo en la DB, pero la ventana de contexto del modelo es finita. Conversaciones largas perderán mensajes antiguos. -
El timeout por defecto (60s) se queda corto con tools web. Subir a 120s evita cortes cuando el agente encadena búsquedas.
-
Empieza simple. Un agente con instrucciones claras y una sola tool ya es potente. Añade complejidad cuando de verdad la necesites. Si prefieres TypeScript, el tutorial del Claude Agent SDK sigue exactamente esta filosofía: un agente, una herramienta y un prompt bien diseñado.
-
Cuida la privacidad. Si usas
RemembersConversations, estás guardando mensajes del usuario en tu base de datos. Dependiendo del contexto, eso es dato sensible. Valora cifrado, políticas de retención y, si aplica, cumplimiento con RGPD.
Resumen de ficheros y comandos ¶
Todo el proyecto se resume en 6 ficheros creados a mano:
| Fichero | Qué hace |
|---|---|
app/Ai/Agents/PersonalAssistant.php |
Agente con memoria, tools y provider OpenAI |
app/Ai/Tools/SearchKnowledgeBase.php |
Herramienta RAG con LLPhant |
app/Console/Commands/IngestDocumentation.php |
Comando docs:ingest para indexar .md |
app/Console/Commands/ChatWithAssistant.php |
Comando assistant:chat para terminal |
app/Http/Controllers/AssistantController.php |
Controller con streaming SSE |
resources/views/assistant.blade.php |
Vista del chat web |
Y 3 comandos para ponerlo en marcha:
# 1. Instalar dependencias
composer require laravel/ai theodo-group/llphant
# 2. Publicar config + migrar
php artisan vendor:publish --provider="Laravel\Ai\AiServiceProvider"
php artisan migrate
# 3. Ingestar documentación y chatear
php artisan docs:ingest --fresh
php artisan assistant:chat
Esto es solo el principio ¶
Lo que hemos construido aquí cubre un caso de uso completo: un asistente con RAG, memoria, búsqueda web, interfaz CLI y web. Y todo sobre SQLite y un fichero JSON, sin infraestructura adicional.
Laravel AI SDK es un paquete joven (v0.1.3 mientras escribo esto), pero la base es sólida. Quedan cosas por explorar: embeddings nativos con pgvector para producción, vector stores del proveedor con FileSearch, respuestas estructuradas, generación de imágenes, transcripción de audio…
Pero para empezar, con lo que tienes aquí ya puedes construir algo funcional y útil.
Crea tu carpeta docs/, mete tus markdowns, ejecuta docs:ingest y hazle una pregunta a tu asistente. A partir de ahí, cada mejora que añadas tendrá un impacto real.
Y si algo falla, ya sabes: lee el error desde el principio, no desde el final. 😉


Escrito con la ayuda de la IA generativa de Claude, fuentes fidedignas y con un human in the loop:
Dani Primo.
12 recursos para developers cada domingo en tu bandeja de entrada
Además de una skill práctica bien explicada, trucos para mejorar tu futuro profesional y una pizquita de humor útil para el resto de la semana. Gratis.